Microsoft
[Microsoft Azure] Azure Data Lake Storage Gen2 소개
truthyun
2024. 11. 12. 10:41
728x90
반응형
Azure Data Lake Storage Gen2
- Data Lake는 일반적으로 Blob 또는 파일로 저장된 해당 기본 형식의 데이터 리포지토리
- Azure에 구축된 빅데이터 분석을 위한 포괄적이고 확장성이 있는 비용 효육적인 Data Lake 솔루션
- 파일 시스템과 스토리지 플랫폼을 결합하여 데이터에 대한 인사이트를 빠르게 파악할 수 있도록 지원
- Azure Blob 스토리지 기능을 기반으로 하여 특히 분석 워크로드에 맞게 최적화
- 분석 성능, Blob 스토리지의 계층화 및 데이터 수명 주기 관리 기능, Azure Storage의 고가용성, 보안 및 내구성 기능을 사용할 수 있음.
이점
- 수백 기가바이트의 처리량을 안전하게 처리하면서 엑사바이트 규모의 데이터의 양과 다양성을 처리하도록 설계되어 Data Lake Storage Gen2를 실시간 및 일괄 처리 솔루션의 기초로 사용할 수 있음.
Hadoop 호환 액세스
- 데이터를 Hadoop 분산 파일 시스템(HDFS)에 저장된 것처럼 처리할 수 있다.
- 환경 간에 데이터를 이동하지 않고도 Azure Databricks, AzureHDIsight 및 Azure Synapse Analytics를 포함한 컴퓨팅 기술을 통하 한 곳에 데이터를 저장하고 액세스할 수 있다.
- 내부 열 형식 스토리지를 사요하여 여러 플랫폼에서 고도로 압축되고 잘 수행되는 parquet 형식과 같은 스토리지 매커니즘을 사용할 수 있다.
보안
- 부모 디렉터리의 사용 권한을 상속하지않는 ACL(액세스 제어 목록) 및 POSIX(이식 가능한 운영 체제 인터페이스) 권한 지원
- Data Lake 내에 저장된 데이터에 대한 디렉터리 수준 또는 파일 수준에서 권한을 설정해 안전한 스토리지 시스템을 제공
- Hive 및 Spark와 같은 기술 또는 Azure Storage Explorer와 같은 유틸리티를 통해 구성할 수 있다.
성능
- 저장된 데이터를 파일 시스템처럼 디렉터리와 하위 디렉터리의 계층구조로 구성하여 더 쉽게 탐색할 수 있도록 해 데이터 처리에 계산 리소스를 덜 필요로 하며, 이로 인해 시간과 비용 모두 절감
데이터 중복성
- LRS(로컬 중복 스토리지)를 사용하여 단일 데이터 센터에 또는 GRS 옵션을 사용하여 보조 지역에 데이터 중복성을 제공하는 Azure Blob 복제 모델을 활용
- 재해가 발생하는 경우에도 데이터를 항상 사용할 수 있고 보호할 수 있음
Azure Storage에서 ADLS Gen2 사용
- Azure Data Lake Storage Gen2는 독립 실행형 Azure 서비스가 아니라 StorageV2(범용 V2) Azure Storage의 구성 가능한 기능이다.
- Azure Portal 스토리지 계정을 만들 때 고급 페이지에서 계층 구조 네임스페이스 사용 옵션을 선택
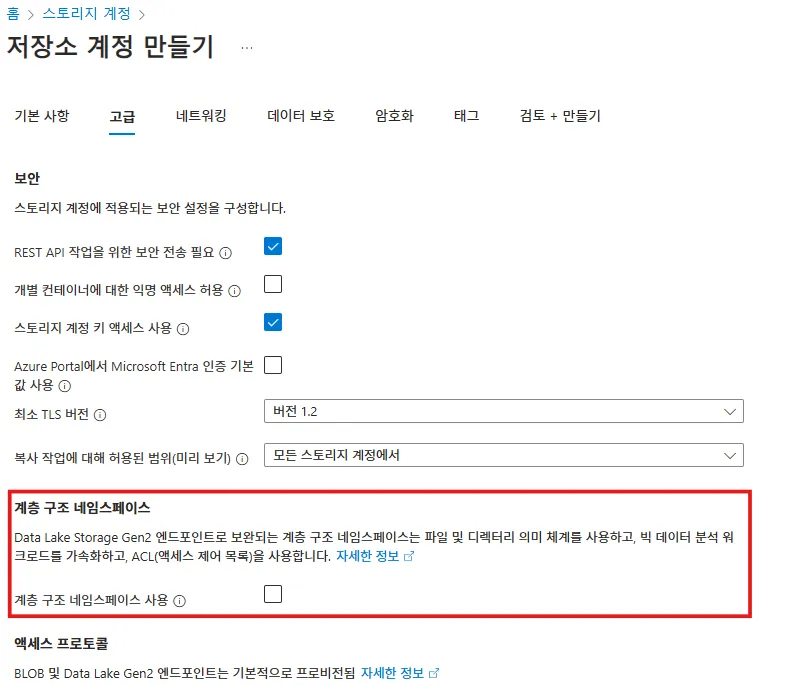
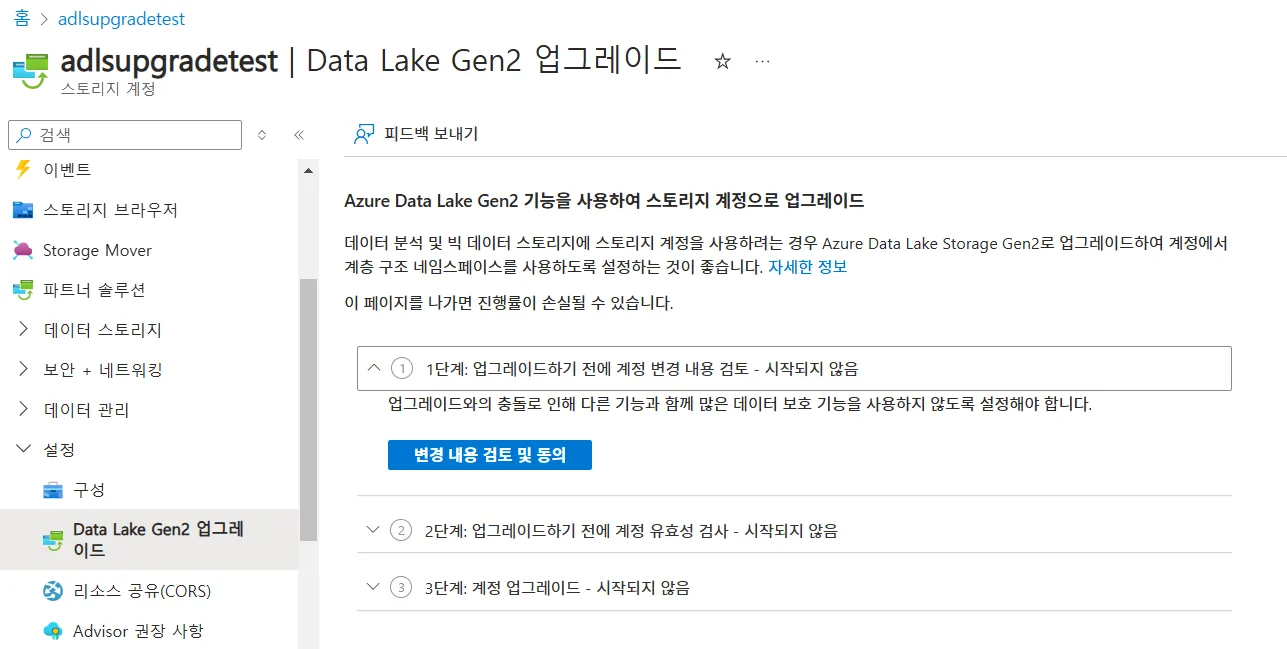
- Azure Storage 계정이 이미 있고, ADLS Gen2 기능을 사용하도록 설정하려는 경우, 스토리지 계정 리소스에 대한 Azure Portal 페이지에서 Data Lake Gen2 업그레이드 마법사를 사용할 수 있다.
- 스토리지 계정 리소스 > 설정 > Data Lake Gen2 업그레이드
Azure Data Lake Store와 Azure Blob Storage 비교
Azure Blob Storage
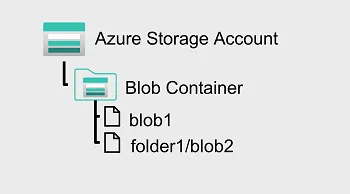
- 대량의 비정형 개체 데이터를 Blob 컨테이너 내의 단일 구조 네임스페이스에 저장할 수 있다.
- Blob 이름에는 Blob을 가상폴더로 구정하는”/” 문자가 포함될 수 있지만 Blob 관리 효율성 측면에서 Blob은 단일 구조 네임스페이스에 단일 수준 계층 구조로 저장
- HTTP 또는 HTTPs를 사용하여 데이터에 액세스
Azure Data Lake Storage Gen2
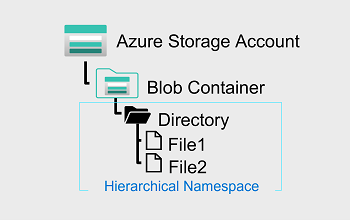
- Blob Storage를 기반으로 하며, Blob 데이터를 디렉터리로 구성하고, 각 디렉터리와 그 안에 있는 파일에 대한 메타데이터를 저장하는 계층 구조 네임스페이스를 사용하여 대용량 데이터의 I/O를 최적화
- 이 구조를 사용하면 디렉터리 이름 바꾸기 및 삭제와 같은 작업을 단일 원자성 작업으로 수행할 수 있다.
- 단일 구조 네임 스페이스에는 구조의 개체수에 비례한 몇 가지 작업이 필요
- 데이터를 체계적으로 유지하므로 분석 사용 사례의 스토리지 검색 성능이 향상, 분석 비용이 절감
빅데이터 처리를 위한 단계 이해
- Data Lake는 광범위한 빅데이터 아키텍처에서 기본적인 역할 수행
- Enterprice Data Warehouse
- 빅데이터에 대한 고급 분석
- 실시간 분석 솔루션
수집
- 원본 데이터를 가져오는 데 사용되는 기술과 프로세스 식별
- 데이터는 Data Lake에 저장해야하는 파일, 로그 및 다른 형식의 비정형 데이터에서 가져올 수 있다.
- Ex. Azure Synapse Analytics 또는 Azure Data Factory의 Pipline
- 실시간 데이터 수집의 경우 HDInsight용 Apache Kafka 또는 Stream Analytics 사용 가능
저장
- 수집된 데이터를 배치할 위치 식별
- ADLS Gen2는 일반적으로 사용되는 빅데이터 처리 기술과 호환되는 안전하고 확장가능한 스토리지 솔루션 제공
준비 및 학습
- 데이터 준비와 기계 학습 솔루션에 대한 모델 학습 및 채점을 수행하는데 사용되는 기술 식별
- Ex. Azure Synapese Analytics, Azure Databricks, Azure HDInsight 또는 Azure Machine Learning Service
모델 및 제공
- 사용자에게 데이터를 제공하는 기술 사용
- Ex. Microsoft Power BI, Azure Synapse Analytics
데이터 분석 워크로드에서 Azure Data Lake Storage Gen2 사용
빅데이터 처리 및 분석
- 빅데이터 시나리오는 일반적으로 빠른 속도로 처리해야하는 다양한 형식의 대규모 데이터를 포함하는 분석 워크로드 참조
- Azure Synapse Analytics, Azure Databricks 및 Azure HDInsight와 같은 빅데이터 서비스가 Apache Spark, Hive 및 Hadoop과 같은 데이터 처리 프레임워크를 적용할 수 있는 확장 가능하고 안전한 분산 데이터 저장소를 제공
- 스토리지 및 처리 컴퓨팅의 분산 특성을 통해 작업을 병렬로 수행할 수 있으므로 대량의 데이터를 처리하는 경우에도 고성능 및 확장성이 향상됨.
데이터 웨어하우징
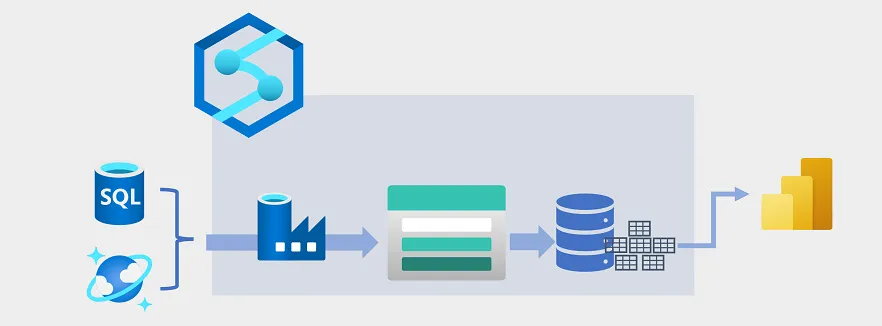
- Azure Synapse Analytics가 ADF를 사용해 ETL 프로세스를 수행하기 위한 Pipline 호스트
- SQL DB와 Azure Cosmo로 부터 운영 데이터 원본에서 데이터를 추출하고 ADLS Gen2컨테이너에 호스트 되는 Lake에 로드
- 그 후 데이터는 처리되고 Power BI를 사용해 데이터 시각화 및 보고를 지원할 수 있는 Datla Lake에 로드
- 데이터 처리 후 Power Bi를 사용해 데이터 시각화 및 보고를 지원할 수 있는 Azure Synapse Analytics 전용 SQL풀의 관계형 Data Warehouse에 로드
- 일반적으로 Azure SQL 데이터베이스 또는 Azure Cosmos DB와 같은 운영 데이터 저장소에서 추출되고 분석 워크로드에 더 적합한 구조로 변환
- 관계형 Data Warehouse에 로드되기 전에 분산 처리를 용이하게 하기 위해 데이터가 Data Lake에서 스테이징 되는 경우가 많다
- 경우에 따라 Data Warehouse는 External Table을 사용하여 Data Lake의 파일에 대한 관계형 메타데이터 계층을 정의하고 하이브리드 Data Lakehouse 또는 Lake Database를 만든 후, Data Warehouse는 보고 및 시각화에 대한 분석 쿼리를 지원할 수 있다.
실시간 데이터 분석
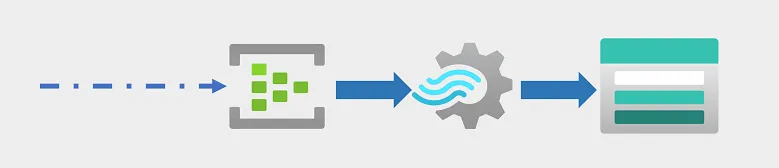
- Azure Stream Anlaytics에서 Azure Event Hubs로 부터의 입력 스트림을 변환하여 저장
- Data Stream은 연결된 디바이스, 소셜 미디어 플랫폼 또는 기타 애플리케이션의 사용자가 생성한 데이터에서 생성할 수 있다.
- 스트리밍 데이터 이벤트가 발생 했을 때 무한한 데이터 스팀을 캡처하고 처리할 수 있는 솔루션 필요
- Azure Stream Analytics를 사용해 이벤트 데이터가 도착할 때 쿼리 및 집계하는 작업을 만들고 결과를 출력 싱크에 사용 가능
- 이러한 싱크 중 하나가 캡처된 실시간 데이터를 분석하고 시각화할 수 있는 Azure Data Lake Storage Gen2
데이터 과학 및 기계학습

- 데이터 과학에는 대용량 데이터의 통계 분석이 포함되며, 종종 Apache Spark와 같은 도구 및 Python과 같은 스크립팅 언어를 사용한다.
- Azure Data Lake Storage Gen 2는 데이터 과학 워크로드에 필요한 대량의 데이터에 대해 확장성이 뛰어난 클라우드 기반 데이터 저장소를 제공
- 기계 학습은 데이터 과학의 하위 집합으로, 예측 모델링을 다룬다.
- Azure Machine Learning은 데이터 과학자가 동적으로 할당된 분산 컴퓨팅 리소스를 사용하여 Notebook에서 Python 코드를 실행할 수 있는 클라우드 서비스
- 컴퓨팅은 Azure Data Lake Storage Gen2 컨테이너의 데이터를 처리하여 모델을 학습시킨 다음, 예측 분석 워크로드를 지원하기 위해 프로덕션 웹 서비스로 배포할 수 있다.
728x90
반응형