
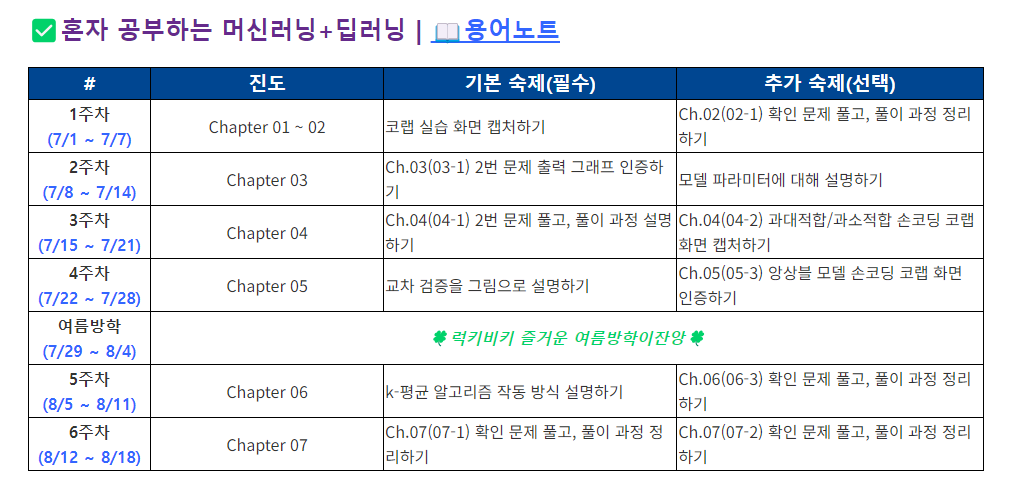
[기본 숙제]
k-평균 알고리즘은 주어진 데이터를 k개의 클러스터로 묶는 알고리즘으로, 각 클러스터와 거리 차이의 분산을 최소화하는 방식으로 동작한다. 자율 학습의 일종으로, 레이블이 달려 있지 않은 입력 데이터에 레이블을 달아주는 역할을 수행한다
K-평균 알고리즘 작동 방식
1. 무작위로 K개의 클러스터 중심 정하기
2. 각 샘플에서 가장 가까운 클러스터 중심을 찾아 해당 클러스터의 샘플로 지정
3. 클러스터에 속한 샘플의 평균값으로 클러스터 중심 변경
4. 클러스터 중심에 변화가 없을 때 까지 2번으로 돌아가 반복
[추가 숙제]

1. 일반적으로 데이터 셋에서 주성분은 특성의 개수만큼 찾을 수 있다.
2. (1000, 100) 크기 데이터셋에서 10개의 주성분을 찾아 변환하면 샘플의 수는 그대로 존재하며, 특성의 수는 주성분의 개수와 동일한 10이 된다. 따라서 변환된 데이터셋의 크기는 (1000, 10)이 된다.
3. 주성분 분석은 차원 축소 알고리즘의 하나로, 데이터에서 가장 분산이 큰 방향을 찾는 방법이다. 여기서 설명된 분산은 중성분 분석에서 주성분이 얼마나 원본 데이터의 분산을 잘 나타내는지 기록한 값을 의미한다.
따라서 분산이 가장 큰 순서대로 찾기 때문에 첫번째 주성분의 설명된 분산이 가장 크다고 할 수 있다.
군집분석과 주성분 분석은 내가 가장 흥미롭게 배웠던 교과과정 중 하나였기에 이번 주차는 너무나 재밋게 배울 수 있었다. 내용자체는 익숙했지만 SAS로 이 과정을 배웠기 때문에 파이썬으로 실습해보니 한편으로는 새로운 내용이어서 익숙하면서도 새로웠다! 혼공머신 책 덕분에 한층 더 똑똑해진 기분이었다 ><
'Study > ML | DL' 카테고리의 다른 글
| [혼공머신]6주차_딥러닝을 시작합니다 (1) | 2024.08.20 |
|---|---|
| [혼공머신]4주차_트리 알고리즘 (0) | 2024.07.28 |
| [혼공머신]3주차_다양한 분류 알고리즘 (0) | 2024.07.21 |
| [혼공머신]2주차_회귀 알고리즘과 모델 규제 (1) | 2024.07.14 |
| [혼공머신]1주차_머신러닝을 찍먹해보자! (0) | 2024.07.07 |
[기본 숙제]
k-평균 알고리즘은 주어진 데이터를 k개의 클러스터로 묶는 알고리즘으로, 각 클러스터와 거리 차이의 분산을 최소화하는 방식으로 동작한다. 자율 학습의 일종으로, 레이블이 달려 있지 않은 입력 데이터에 레이블을 달아주는 역할을 수행한다
K-평균 알고리즘 작동 방식
1. 무작위로 K개의 클러스터 중심 정하기
2. 각 샘플에서 가장 가까운 클러스터 중심을 찾아 해당 클러스터의 샘플로 지정
3. 클러스터에 속한 샘플의 평균값으로 클러스터 중심 변경
4. 클러스터 중심에 변화가 없을 때 까지 2번으로 돌아가 반복
[추가 숙제]
1. 일반적으로 데이터 셋에서 주성분은 특성의 개수만큼 찾을 수 있다.
2. (1000, 100) 크기 데이터셋에서 10개의 주성분을 찾아 변환하면 샘플의 수는 그대로 존재하며, 특성의 수는 주성분의 개수와 동일한 10이 된다. 따라서 변환된 데이터셋의 크기는 (1000, 10)이 된다.
3. 주성분 분석은 차원 축소 알고리즘의 하나로, 데이터에서 가장 분산이 큰 방향을 찾는 방법이다. 여기서 설명된 분산은 중성분 분석에서 주성분이 얼마나 원본 데이터의 분산을 잘 나타내는지 기록한 값을 의미한다.
따라서 분산이 가장 큰 순서대로 찾기 때문에 첫번째 주성분의 설명된 분산이 가장 크다고 할 수 있다.
군집분석과 주성분 분석은 내가 가장 흥미롭게 배웠던 교과과정 중 하나였기에 이번 주차는 너무나 재밋게 배울 수 있었다. 내용자체는 익숙했지만 SAS로 이 과정을 배웠기 때문에 파이썬으로 실습해보니 한편으로는 새로운 내용이어서 익숙하면서도 새로웠다! 혼공머신 책 덕분에 한층 더 똑똑해진 기분이었다 ><
'Study > ML | DL' 카테고리의 다른 글
| [혼공머신]6주차_딥러닝을 시작합니다 (1) | 2024.08.20 |
|---|---|
| [혼공머신]4주차_트리 알고리즘 (0) | 2024.07.28 |
| [혼공머신]3주차_다양한 분류 알고리즘 (0) | 2024.07.21 |
| [혼공머신]2주차_회귀 알고리즘과 모델 규제 (1) | 2024.07.14 |
| [혼공머신]1주차_머신러닝을 찍먹해보자! (0) | 2024.07.07 |