
지난 포스팅에서 DataFrame에서 행, 열을 중심으로 선택, 필터링 하는 방법에 대해 소개해보았습니다.
DataFrame의 행을 선택할 때는 인덱스, loc함수, 컬럼의 조건을 통한 검색 등 다양한 방법이 있었고, 열을 선택할 때는 열이름을 이용하거나 filter 함수의 옵션들을 통해 다양하게 필터링하는 방법에 대해 써보았습니다. 오늘은 DataFrame에서 행 또는 열을 삭제하는 방법에대해 소개해드리겠습니다.
[Python]Pandas Basic 파이썬 판다스 기본 : 데이터프레임 다루기
지난 포스팅에서는 Pandas 를 이용해 DataFrame을 만들고, 만든 DataFrame을 저장하는 과정에 대해 알아보고 실습해보았습니다. 오늘은 DataFrame에서 행을 중심으로, 그리고 열을 중심으로 선택, 필터링
seoyuun22.tistory.com
6. Drop row or column
데이터가 크고 많다고 해서 항상 모든 데이터가 필요 있는것은 아닙니다. 어떤사람에겐 필요할 수도 있고, 필요 없을 수 도 있죠. 필요 한 데이터는 그대로 두면 되지만 필요없다고 판단되는 데이터는 과감히 삭제하는게 데이터를 분석하는데 좀더 긍정적인 영향을 미칠것 입니다. 그렇다면 DataFrame에서 행, 또는 열을 삭제하고 싶을 때, 어떻게 하는게 좋을까요?
1 ) drop 함수를 이용한 행 또는 열 삭제
아래 코드를 이용하여 DataFrame의 행 또는 열을 삭제해보겠습니다.
import pandas as pd
friends = [
{'age' : 15, 'job' : 'student'},
{'age' : 25, 'job' : 'developer'},
{'age' : 30, 'job' : 'teacher'},
]
df = pd.DataFrame(friends,
index = ['John', 'Jenny', 'Nate'],
columns = ['age', 'job'])

위의 코드를 작성해 실행해 보면 age와 job을 column으로 갖고, 이름을 인덱스로 갖는 DataFrame이 만들어 집니다.
여기서 'John'과 'Nate'의 정보를 삭제하고 싶을 때 drop이라는 함수를 사용해 삭제할 수 있습니다. drop 함수는 다음과 같이 씁니다.
.drop()
# drop row
dataframe.drop(['index'])
# drop column
dataframe.drop(['column_name'], axis=1)
dataframe.drop(columns = ['column_name')])drop 함수를 통해 행, 열을 모두 삭제할 수 있습니다. 행을 삭제할 때는 인덱스를 이용해, 열을 삭제할 때는 열 이름을 이용해 삭제합니다. 행에서 쓰는 인덱스는 위의 데이터와 같이 인덱스가 어떠한 문자열일때 뿐만 아니라 row 번호일 때도 사용할 수 있습니다.
일단 가장 먼저 행 기준으로 'John'과 'Nate'의 정보를 삭제해보겠습니다.

drop 함수를 사용해 'John'과 'Nate'의 정보를 삭제했더니 Jenny의 정보만 남았습니다. 그러나 drop함수를 썼을 때만 이렇게 보이는거지 df를 다시 보면 drop된 상태가 저장되어있지 않고 데이터의 원본이 남아있음을 확인할 수 있습니다.
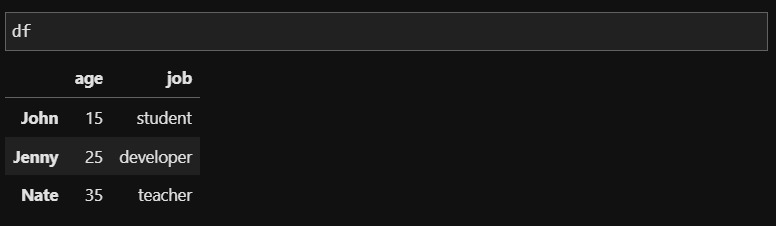
그래서 만약 삭제한 상태를 저장하고 싶다면, df = df.drop(['John', 'Nate']) 으로 저장하면 삭제된 상태를 저장할 수 있습니다. 하지만 drop 함수의 옵션을 설정하면 한번에 삭제한 상태를 저장할 수 있습니다.
.drop(inplace=True)
inplace 옵션의 기본형은 False로, 옵션을 지정하지 않으면 복사본을 반환합니다. 그러나 True일 경우 삭제된 정보를 dataframe에 바로 적용하여 출력합니다.
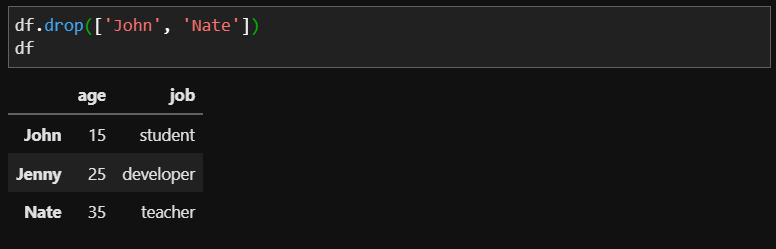
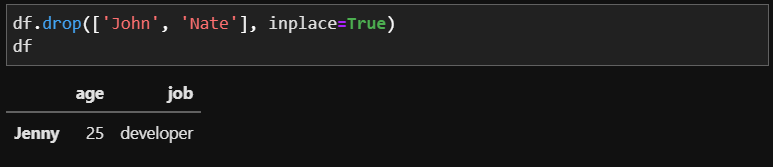
inplace = True를 하면 번거롭게 df에 다시 저장하지 않아도 정보가 삭제되어 df에 저장되었음을 확인할 수 있습니다. (중간중간 inplace 옵션을 사용했다면 데이터를 복원시켜주세요! 안그럼 에러가 발생합니다.)
이번엔 아래 코드를 바탕으로 만들어진 DataFrame을 이용하여 row의 인덱스가 숫자 일때 행을 삭제한 방법에 대해 보겠습니다.
friends = [
{'name' : 'John', 'age' : 15, 'job' : 'student'},
{'name' : 'Ben', 'age' : 25, 'job' : 'developer'},
{'name' : 'Jenny', 'age' : 30, 'job' : 'teacher'},
]
df = pd.DataFrame(friends,
columns = ['name','age', 'job'])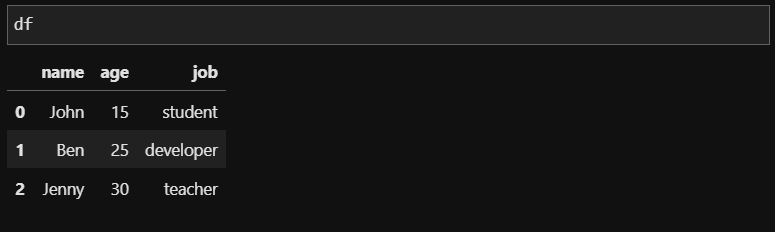
이전에 만들었던 DataFrame과 다르게 인덱스 이름 없이 번호로 되어있는 DataFrame입니다. 여기서 행번호를 이용해 삭제해보겠습니다. 이번에는 John과 Jenny의 정보를 삭제해보겠습니다. Jonh의 번호는 0, Jenny는 2번이니까 0번째, 2번쩨 데이터를 삭제 해주면 됩니다.

이때도 아무런 옵션이 없다면 drop 함수를 썼다 해도 df에는 데이터 원본이 저장되어있습니다. 만약 삭제된 것을 바로 적용하려면 위에서 봤던 inplace 옵션으로 삭제한 DataFrame이 저장될 것입니다.
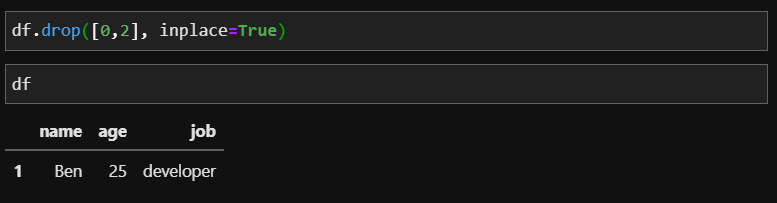
+) index 인스턴스를 사용해 위의 인덱스로 삭제하는 방법과 같은 기능을 할 수도 있습니다

조건에 맞는 데이터 drop
이전에 행, 열을 필터링할 때 조건식을 이용하여 선택했었던것 처럼 데이터를 삭제할 때도 조건식을 이용하여 조건에 맞는 데이터만 삭제 할 수 있습니다. 예를 들어 age가 20살 이하인 사람의 데이터를 삭제한다고 하면 다음과 같이 쓸 수 있습니다.
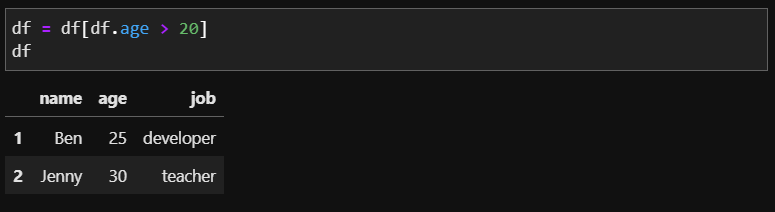
age가 20세 이하인 사람의 데이터를 삭제한다는 것은 나이가 20보다 큰 사람만을 저장하겠다는 의미니까 'age > 20' 로 작성하여 조건을 만족하는 정보만을 남기고 조건을 만족하지 못하는 정보는 제외하여 새롭게 df에 저장함으로 삭제할 수 있습니다.
이제까지는 '행'을 기준으로 삭제해왔다면, 이번에는 '열'을 기준으로 삭제해보겠습니다. 열을 기준으로 삭제할 때도 행을 삭제할때와 마찬가지로 drop함수를 사용합니다. 열을 삭제하는 방법에는 2가지가 있는데, 이는 옵션을 어떻게 두느냐 차이입니다.
axis 옵션
axis 옵션은 지난 필터링 글에서도 봤던 옵션으로, 기준 축을 결정하는 옵션입니다. 0은 행, 1은 열을 의미합니다. 이번에는 열 기준으로 삭제할꺼니까 당연히 axis = 1이 될 것입니다.
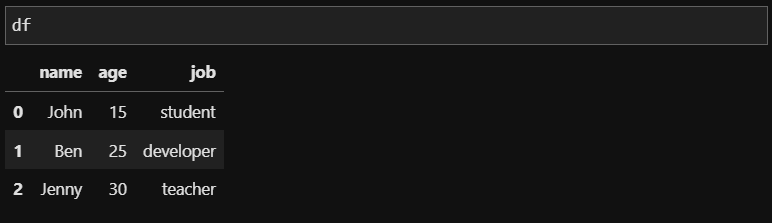
예제로 사용할 DataFrame은 위와 같습니다. 이제 여기서 열을 기준으로 두고 'age' 정보만을 삭제해보겠습니다.
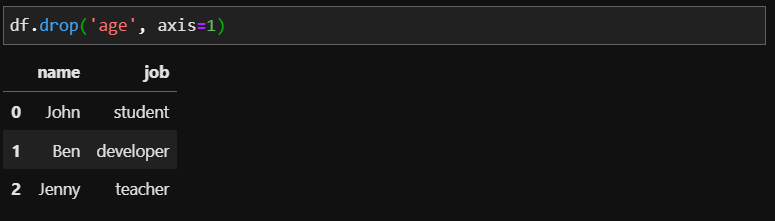
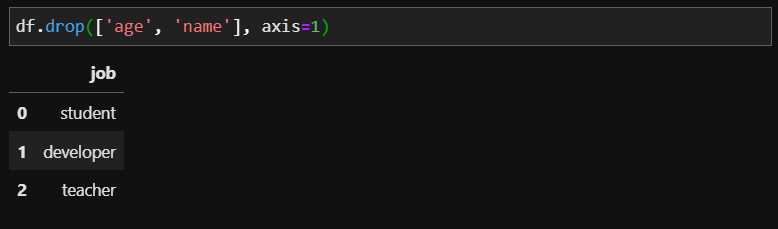
axis 옵션과 함께 삭제할 'age'를 입력하니 age 정보가 없어진것을 확인할 수 있습니다. 또한 대괄호로 여러 컬럼명을 묶어 2개 이상의 컬럼을 삭제할 수도 있습니다. 여기서도 df는 아직 원본데이터를 갖고 있기 때문에 위의 결과를 바로 적용하여 저장하려면 inplace = True 옵션을 지정해야 합니다.
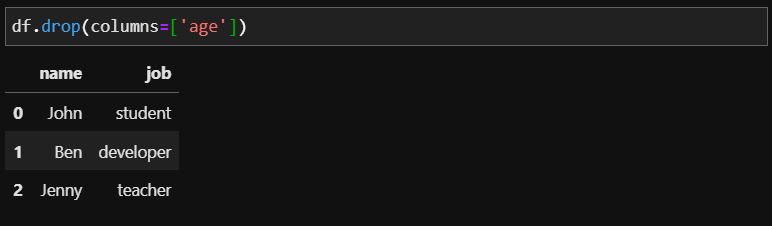
columns 옵션
aixs 옵션은 기준 축을 정하는 옵션으로 기준축을 변경하는 옵션이었다면 columns는 대놓고 열을 삭제하겠다! 입니다. columns 옵션에는 리스트 형태의 컬럼명을 받아 열을 삭제합니다.
'Study > Python' 카테고리의 다른 글
| [Python]Pandas basic 파이썬 판다스 기초 : 데이터 그룹 만들기, 중복 데이터 삭제 (0) | 2021.08.12 |
|---|---|
| [Python]Pandas basic 파이썬 판다스 기초 : 행,열 생성 및 수정하기 (1) | 2021.07.14 |
| [Python]Pandas Basic 파이썬 판다스 기본 : 데이터프레임 다루기 (0) | 2021.06.28 |
| [Python] pandas basic 파이썬 판다스 기본 : DataFrame 만들기, 저장하기 (0) | 2021.06.23 |
| [Python] pandas basic: 파이썬 판다스 기본: 개념, 데이터 불러오기 (1) | 2021.06.21 |