
지난 포스팅에서는 DataFrame에서 행이나 열을 삭제하지 않고 수정하거나 새로운 행, 열을 만들어 내는 방법에 대해 글을 써보았습니다.
[Python]Pandas basic 파이썬 판다스 기초 : 행,열 생성 및 수정하기
지난 포스팅에서는 DataFrame에서 행과 열을 삭제하는 방법에 대해서 소개해보았습니다. DataFrame에서 행 또는 열을 삭제할 때는 drop 함수를 주로 사용했고, drop 함수를 사용하면서 여러 옵션에 대해
seoyuun22.tistory.com
오늘은 pandas에서 groupby 함수로 데이터 그룹을 만드는 법과 중복 데이터를 삭제하는 방법에 대해 배워보겠습니다.
8. Group by column
데이터를 관찰할 때, 특정 컬럼을 기준으로 볼 때가 있습니다. 성별을 기준으로, 연령을 기준으로 등 지금부터 살펴볼 groupby 함수는 이런 경우에 유용하게 쓸 수 있는 함수입니다. groupby는 열(column) 정보로 데이터 그룹을 만들 때 사용합니다. 또한 그룹을 만들어 연산을 계산하는 데 사용할 수 있는 함수입니다.
A groupby operation involves some combination of splitting the object, applying a function, and combining the results. This can be used to group large amounts of data and compute operations on these groups.
먼저 groupby를 실습해보기 위해 데이터를 불러오겠습니다.
student_list라는 학생의 이름과 전공, 성별의 정보가 있는 txt 파일입니다. 이 파일을 저장하고, 알맞은 경로와 함께 데이터를 불러옵니다.
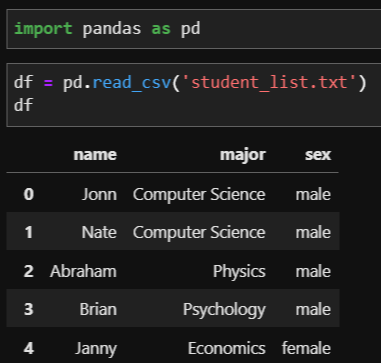
사진에는 5명의 정보만 나와있지만 실제로 보면 11명의 정보를 담고 있는 txt 파일입니다. 이전에 배웠던 파일을 불러오는 다양한 방법으로 데이터를 df에 저장했습니다.
Ex ) Major Group
groupby 함수를 쓸 때, 사용자가 원하는 특정 컬럼을 지정하여 그룹핑할 수 있습니다. 먼저 전공 별로 학생을 그룹핑할 경우 groupby 괄호 안에 전공 정보가 있는 'major'컬럼을 지정합니다. 그룹핑 후 groups 메서드를 이용하면 그룹에 대한 정보를 확인할 수 있습니다.
major = df.groupby('major')
major.groups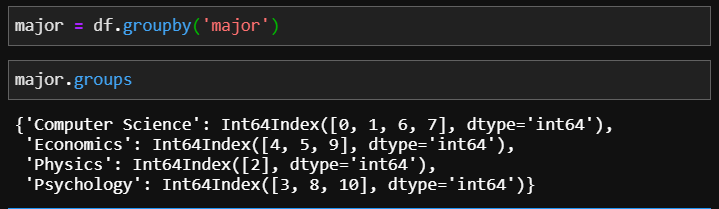
위의 결과를 좀 더 보기 쉽게 만들어 보겠습니다.
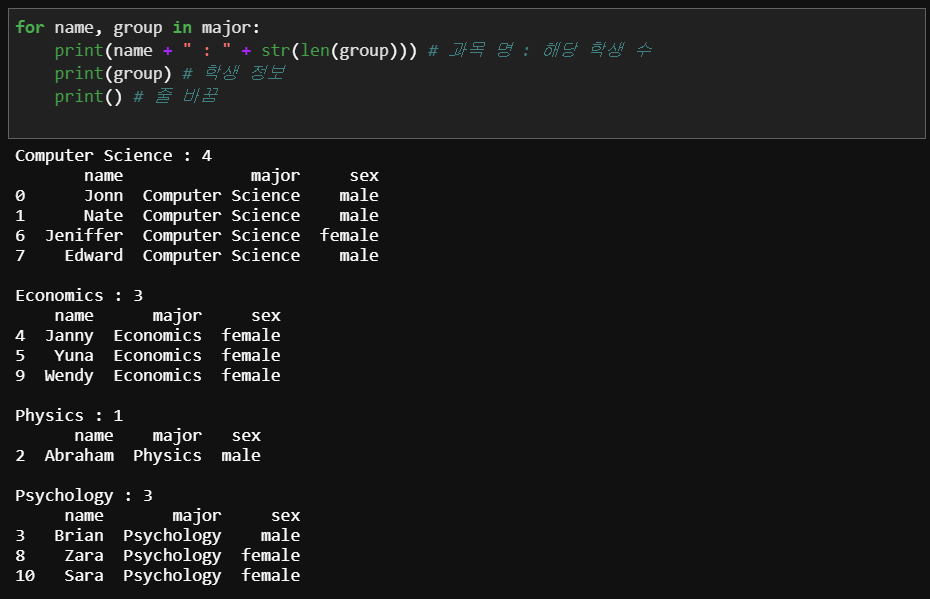
반복문을 통해 전공명과, 해당 과목을 전공하고 있는 학생에 대한 정보를 받아들여 해당 과목을 전공으로 하는 학생은 몇 명인지, 누가 있는지 한눈에 볼 수 있도록 하겠습니다.
위의 정보에서 각 전공 당 학생 수를 dataframe으로 바꾸고 싶은 경우 pandas의 DataFrame 함수를 이용하여 쉽게 변환하여 나타낼 수 있습니다.
major_cnt = pd.DataFrame({'count' : major.size()})
major_cnt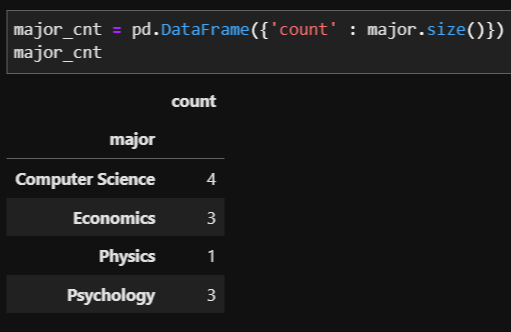
이렇게 할 경우 reset_index를 통해 major를 column으로 바꾸어 나타내면 좀 더 자연스러운 dataframe이 됩니다
major_cnt = major_cnt.reset_index()
major_cnt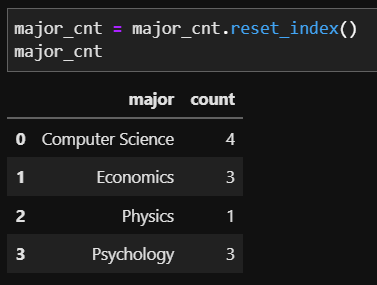
여기서 더 많은 실습을 위해 각 학생들의 중간고사, 기말고사 성적에 대한 정보를 추가해보겠습니다.

중간고사 점수를 mid 컬럼에, 기말고사 점수를 final 컬럼에 추가하고 확인했습니다. 위에서 했던 것처럼 전공을 기준으로 groupby 한 후 각 전공별 성적을 비교해보겠습니다.
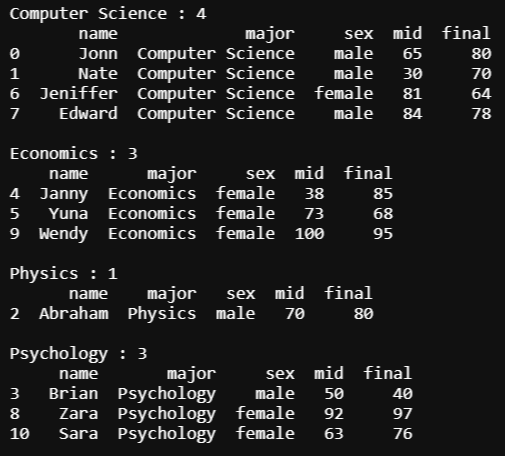
이렇게 보면 어떤 전공생들의 성적이 좋은지 비교하기 어렵습니다. 반복문을 조금 수정해서 전공 별 중간고사와 기말고사 평균점수의 정보를 추가해 좀 더 보기 좋게 해 보겠습니다.
for name, group in major:
print(name + " : " + str(len(group))) # 과목 명 : 해당 학생 수
print(group) # 학생 정보
print("average")
print("mid test : " + str(group['mid'].mean()) +
" final test : " + str(group['final'].mean()))
print() # 줄 바꿈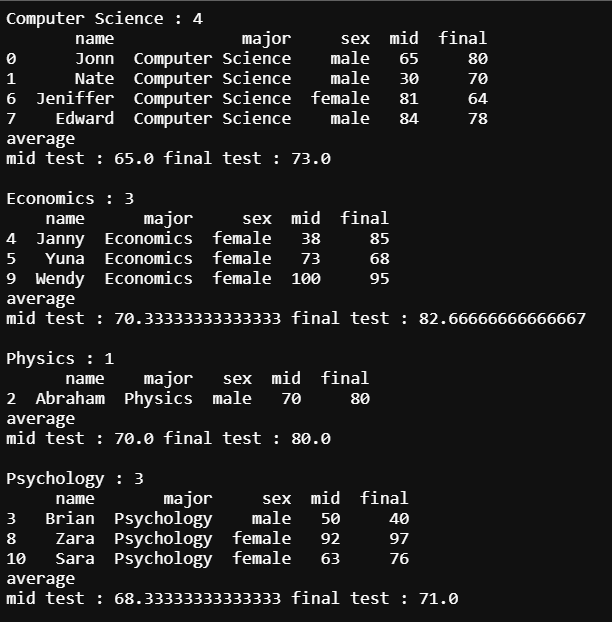
위의 반복문을 통한 출력물에서 중간고사, 기말고사 평균 점수에 대한 정보를 추가해 출력했습니다. 전공에 따른 학생들의 성적을 한눈에 비교하기 쉬워진 것을 확인할 수 있습니다. 뿐 만 아니라 전공 별 평균 성적에 대한 dataframe을 만드는 것 또한 이전에 dataframe을 만들었던 방법과 동일합니다.
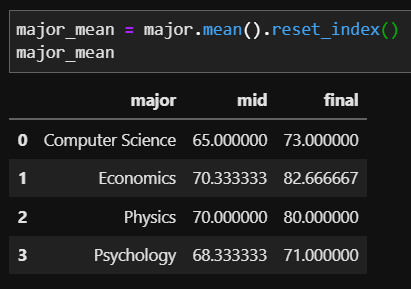
이처럼 groupby 함수를 통해 평균 계산뿐만 아니라 다양한 연산을 할 수 있음을 알 수 있습니다. groupby 함수에 대해 더 자세한 설명과 다양한 예제는 밑에 링크에서 확인할 수 있습니다.
pandas.DataFrame.groupby — pandas 1.3.1 documentation
Used to determine the groups for the groupby. If by is a function, it’s called on each value of the object’s index. If a dict or Series is passed, the Series or dict VALUES will be used to determine the groups (the Series’ values are first aligned; s
pandas.pydata.org
9. Drop Duplicate
데이터를 전처리하는 과정에서 중복되는 데이터를 제거해야 할 때가 있습니다. 중복되는 데이터는 분석에서 발생할 수 있는 혼란을 방지하고자 전처리 과정에서 미리 제거할 필요가 있습니다. 이러한 경우를 대비해 중복 여부를 확인하고, 이를 제거하는 것 까지 실습해보겠습니다.
# 예제 데이터 코드
import pandas as pd
student_list = [{'name' : 'John',
'major' : 'Computer Science', 'sex' : 'male'},
{'name' : 'Nate',
'major' : 'Computer Science', 'sex' : 'male'},
{'name' : 'Edward',
'major' : 'Computer Science', 'sex' : 'male'},
{'name' : 'Zara',
'major' : 'Psychology', 'sex' : 'female'},
{'name' : 'Wendy',
'major' : 'Economics', 'sex' : 'female'},
{'name' : 'Nate',
'major' : None, 'sex' : 'male'},
{'name' : 'John',
'major' : 'Computer Science', 'sex' : 'male'},
{'name' : 'John',
'major' : 'Economics', 'sex' : 'male'},
]
df = pd.DataFrame(student_list, columns=['name', 'major', 'sex'])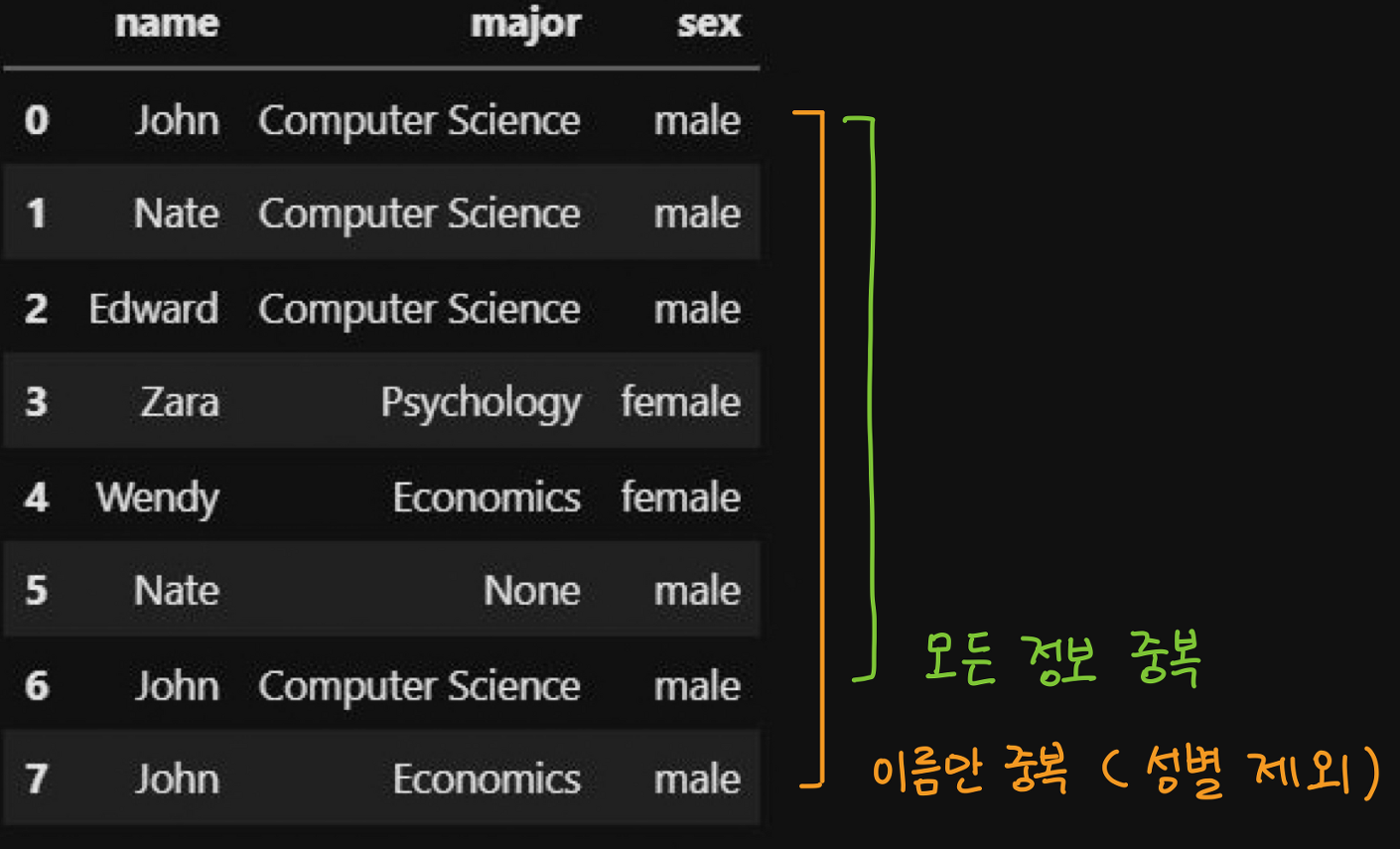
위 코드를 바탕으로 만들어진 dataframe을 살펴보면 0행 정보와 비교했을 때 6행은 모든 정보가 완전히 동일한 경우이며, 7행의 경우 이름은 동일하지만 전공(major)이 다른 것을 확인할 수 있습니다. 이 두 가지 중복된 경우를 확인하는 방법과 제거하는 방법을 살펴보겠습니다.
1. 완전한 데이터가 중복된 경우 (How to remove duplicate)
완전한 데이터가 중복된 경우, 즉 위 dataframe에서 0행과 6행이 한 dataframe에 있는 경우 duplicated 함수로 중복 여부를 확인할 수 있습니다.
df.duplicated()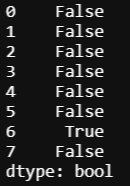
어떤 행과 중복되었는지는 확인할 수 없지만 6번 행에서 중복된 데이터가 발견되었음을 알 수 있습니다. 이제 이 데이터를 제거해야겠죠? 이전 글에서도 얘기했었지만 특정 행, 또는 열을 제거할 때 drop 함수를 쓴다는 것 알고 계신가요? 이것을 이용해서 중복된 행을 제거할 수 있습니다.
※ sum 함수를 실행하면 중복 데이터의 개수를 확인할 수 있습니다.
df.duplicated().sum()특정 행 또는 열을 제거할 때는 drop이었다면, 중복되는 행을 제거할 때는 drop_duplicates 함수를 씁니다. drop_duplicates 또한 drop과 마찬가지로 함수를 실행한다 해도 원 데이터 즉, df 에는 반영되지 않기 때문에 만약 중복이 제거된 dataframe을 반영하고자 하는 경우 inplace = True 옵션을 통해 바로 원 데이터에 적용할 수 있습니다.
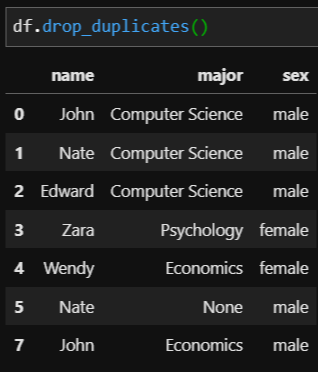
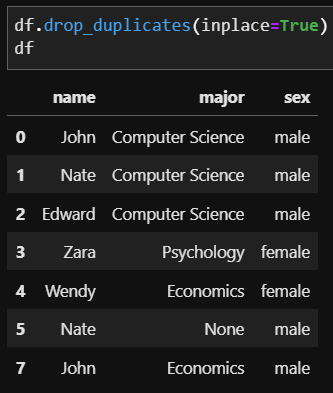
2. 일부 컬럼에 대한 데이터가 중복된 경우 (How to remove duplicate by column value)
일부 컬럼에 대해 중복 여부를 확인할 경우 위에서 봤던 duplicate 함수에서 subset 옵션에 특정 컬럼명을 입력하면 해당 컬럼에서의 중복을 검사할 수 있습니다.
# df.duplicated(subset = ['name'])
df.duplicated(['name'])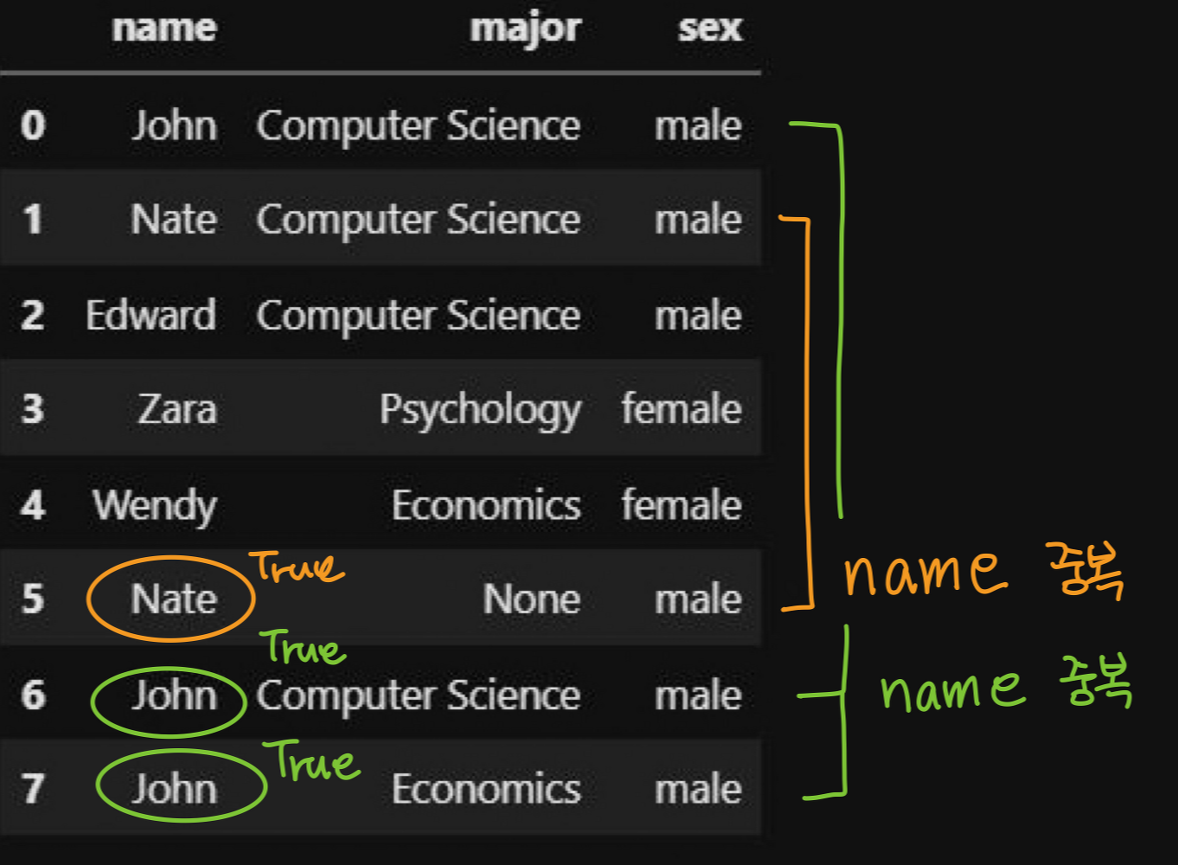
name 컬럼에서 'John'이라는 이름이 6번과 7번 행에서 중복되어 True로, 'Nate'라는 이름 또한 중복되어 5행 또한 True로 출력되는 것을 알 수 있습니다.
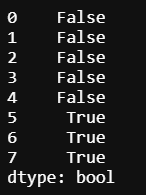
이제 중복되는 행을 제거해보겠습니다. 이 경우에도 이 전과 마찬가지로 drop_duplicates 함수에 특정 컬럼명을 입력하여 특정 행에 대한 중복된 데이터를 제거합니다. 여기서 중복된 행을 제거할 때, 앞에 있는 행을 제거할지 아님 뒤에 있는 행을 제거할지 선택할 수 있는 옵션이 있습니다.
df.drop_duplicates(['name'], keep='first') # 앞의 행 유지
df.drop_duplicates(['name'], keep='last') # 뒤의 행 유지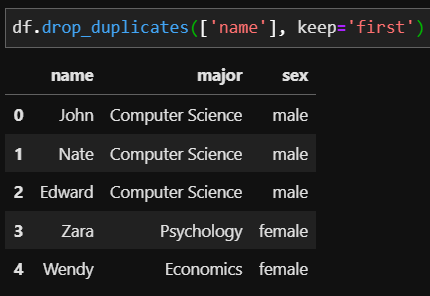
두 결과를 자세히 살펴보면 John이라는 이름의 데이터가 3개가 있었는데 첫 번째, 'first'의 경우 첫 번째 John을 제외한 나머지 두 행이 제거되었음을 알 수 있습니다.
또한 'last'인 경우 가장 마지막에 있던 전공이 Economics 였던 John의 데이터만을 남기고 나머지 두 행이 제거되었음을 알 수 있습니다. keep 옵션의 경우 default 값은 'first'이므로 마지막 중복 값만 남길 경우 keep 옵션에 'last' 값을 지정해주어야 합니다.
오늘은 pandas에서 groupby 함수로 데이터 그룹을 만드는 법과 duplicated 함수로 중복 데이터 여부를 검사하고, drop_duplicates 함수로 중복 데이터를 삭제하는 방법에 대해 알아보았습니다. 다음 포스팅에서는 apply 함수에 대해 집중적으로 다뤄보는 글을 써보겠습니다.
'Study > Python' 카테고리의 다른 글
| [Python]Pandas basic 파이썬 판다스 기초 : map, applymap 함수 활용하기 (0) | 2021.08.18 |
|---|---|
| [Python]Pandas basic 파이썬 판다스 기초 : apply 활용하기 (0) | 2021.08.18 |
| [Python]Pandas basic 파이썬 판다스 기초 : 행,열 생성 및 수정하기 (1) | 2021.07.14 |
| [Python]Pandas basic 파이썬 판다스 기초 : 행,열 삭제 (0) | 2021.06.30 |
| [Python]Pandas Basic 파이썬 판다스 기본 : 데이터프레임 다루기 (0) | 2021.06.28 |
지난 포스팅에서는 DataFrame에서 행이나 열을 삭제하지 않고 수정하거나 새로운 행, 열을 만들어 내는 방법에 대해 글을 써보았습니다.
[Python]Pandas basic 파이썬 판다스 기초 : 행,열 생성 및 수정하기
지난 포스팅에서는 DataFrame에서 행과 열을 삭제하는 방법에 대해서 소개해보았습니다. DataFrame에서 행 또는 열을 삭제할 때는 drop 함수를 주로 사용했고, drop 함수를 사용하면서 여러 옵션에 대해
seoyuun22.tistory.com
오늘은 pandas에서 groupby 함수로 데이터 그룹을 만드는 법과 중복 데이터를 삭제하는 방법에 대해 배워보겠습니다.
8. Group by column
데이터를 관찰할 때, 특정 컬럼을 기준으로 볼 때가 있습니다. 성별을 기준으로, 연령을 기준으로 등 지금부터 살펴볼 groupby 함수는 이런 경우에 유용하게 쓸 수 있는 함수입니다. groupby는 열(column) 정보로 데이터 그룹을 만들 때 사용합니다. 또한 그룹을 만들어 연산을 계산하는 데 사용할 수 있는 함수입니다.
A groupby operation involves some combination of splitting the object, applying a function, and combining the results. This can be used to group large amounts of data and compute operations on these groups.
먼저 groupby를 실습해보기 위해 데이터를 불러오겠습니다.
student_list라는 학생의 이름과 전공, 성별의 정보가 있는 txt 파일입니다. 이 파일을 저장하고, 알맞은 경로와 함께 데이터를 불러옵니다.
사진에는 5명의 정보만 나와있지만 실제로 보면 11명의 정보를 담고 있는 txt 파일입니다. 이전에 배웠던 파일을 불러오는 다양한 방법으로 데이터를 df에 저장했습니다.
Ex ) Major Group
groupby 함수를 쓸 때, 사용자가 원하는 특정 컬럼을 지정하여 그룹핑할 수 있습니다. 먼저 전공 별로 학생을 그룹핑할 경우 groupby 괄호 안에 전공 정보가 있는 'major'컬럼을 지정합니다. 그룹핑 후 groups 메서드를 이용하면 그룹에 대한 정보를 확인할 수 있습니다.
major = df.groupby('major')
major.groups위의 결과를 좀 더 보기 쉽게 만들어 보겠습니다.
반복문을 통해 전공명과, 해당 과목을 전공하고 있는 학생에 대한 정보를 받아들여 해당 과목을 전공으로 하는 학생은 몇 명인지, 누가 있는지 한눈에 볼 수 있도록 하겠습니다.
위의 정보에서 각 전공 당 학생 수를 dataframe으로 바꾸고 싶은 경우 pandas의 DataFrame 함수를 이용하여 쉽게 변환하여 나타낼 수 있습니다.
major_cnt = pd.DataFrame({'count' : major.size()})
major_cnt이렇게 할 경우 reset_index를 통해 major를 column으로 바꾸어 나타내면 좀 더 자연스러운 dataframe이 됩니다
major_cnt = major_cnt.reset_index()
major_cnt
여기서 더 많은 실습을 위해 각 학생들의 중간고사, 기말고사 성적에 대한 정보를 추가해보겠습니다.
중간고사 점수를 mid 컬럼에, 기말고사 점수를 final 컬럼에 추가하고 확인했습니다. 위에서 했던 것처럼 전공을 기준으로 groupby 한 후 각 전공별 성적을 비교해보겠습니다.
이렇게 보면 어떤 전공생들의 성적이 좋은지 비교하기 어렵습니다. 반복문을 조금 수정해서 전공 별 중간고사와 기말고사 평균점수의 정보를 추가해 좀 더 보기 좋게 해 보겠습니다.
for name, group in major:
print(name + " : " + str(len(group))) # 과목 명 : 해당 학생 수
print(group) # 학생 정보
print("average")
print("mid test : " + str(group['mid'].mean()) +
" final test : " + str(group['final'].mean()))
print() # 줄 바꿈위의 반복문을 통한 출력물에서 중간고사, 기말고사 평균 점수에 대한 정보를 추가해 출력했습니다. 전공에 따른 학생들의 성적을 한눈에 비교하기 쉬워진 것을 확인할 수 있습니다. 뿐 만 아니라 전공 별 평균 성적에 대한 dataframe을 만드는 것 또한 이전에 dataframe을 만들었던 방법과 동일합니다.
이처럼 groupby 함수를 통해 평균 계산뿐만 아니라 다양한 연산을 할 수 있음을 알 수 있습니다. groupby 함수에 대해 더 자세한 설명과 다양한 예제는 밑에 링크에서 확인할 수 있습니다.
pandas.DataFrame.groupby — pandas 1.3.1 documentation
Used to determine the groups for the groupby. If by is a function, it’s called on each value of the object’s index. If a dict or Series is passed, the Series or dict VALUES will be used to determine the groups (the Series’ values are first aligned; s
pandas.pydata.org
9. Drop Duplicate
데이터를 전처리하는 과정에서 중복되는 데이터를 제거해야 할 때가 있습니다. 중복되는 데이터는 분석에서 발생할 수 있는 혼란을 방지하고자 전처리 과정에서 미리 제거할 필요가 있습니다. 이러한 경우를 대비해 중복 여부를 확인하고, 이를 제거하는 것 까지 실습해보겠습니다.
# 예제 데이터 코드
import pandas as pd
student_list = [{'name' : 'John',
'major' : 'Computer Science', 'sex' : 'male'},
{'name' : 'Nate',
'major' : 'Computer Science', 'sex' : 'male'},
{'name' : 'Edward',
'major' : 'Computer Science', 'sex' : 'male'},
{'name' : 'Zara',
'major' : 'Psychology', 'sex' : 'female'},
{'name' : 'Wendy',
'major' : 'Economics', 'sex' : 'female'},
{'name' : 'Nate',
'major' : None, 'sex' : 'male'},
{'name' : 'John',
'major' : 'Computer Science', 'sex' : 'male'},
{'name' : 'John',
'major' : 'Economics', 'sex' : 'male'},
]
df = pd.DataFrame(student_list, columns=['name', 'major', 'sex'])위 코드를 바탕으로 만들어진 dataframe을 살펴보면 0행 정보와 비교했을 때 6행은 모든 정보가 완전히 동일한 경우이며, 7행의 경우 이름은 동일하지만 전공(major)이 다른 것을 확인할 수 있습니다. 이 두 가지 중복된 경우를 확인하는 방법과 제거하는 방법을 살펴보겠습니다.
1. 완전한 데이터가 중복된 경우 (How to remove duplicate)
완전한 데이터가 중복된 경우, 즉 위 dataframe에서 0행과 6행이 한 dataframe에 있는 경우 duplicated 함수로 중복 여부를 확인할 수 있습니다.
df.duplicated()어떤 행과 중복되었는지는 확인할 수 없지만 6번 행에서 중복된 데이터가 발견되었음을 알 수 있습니다. 이제 이 데이터를 제거해야겠죠? 이전 글에서도 얘기했었지만 특정 행, 또는 열을 제거할 때 drop 함수를 쓴다는 것 알고 계신가요? 이것을 이용해서 중복된 행을 제거할 수 있습니다.
※ sum 함수를 실행하면 중복 데이터의 개수를 확인할 수 있습니다.
df.duplicated().sum()특정 행 또는 열을 제거할 때는 drop이었다면, 중복되는 행을 제거할 때는 drop_duplicates 함수를 씁니다. drop_duplicates 또한 drop과 마찬가지로 함수를 실행한다 해도 원 데이터 즉, df 에는 반영되지 않기 때문에 만약 중복이 제거된 dataframe을 반영하고자 하는 경우 inplace = True 옵션을 통해 바로 원 데이터에 적용할 수 있습니다.
2. 일부 컬럼에 대한 데이터가 중복된 경우 (How to remove duplicate by column value)
일부 컬럼에 대해 중복 여부를 확인할 경우 위에서 봤던 duplicate 함수에서 subset 옵션에 특정 컬럼명을 입력하면 해당 컬럼에서의 중복을 검사할 수 있습니다.
# df.duplicated(subset = ['name'])
df.duplicated(['name'])name 컬럼에서 'John'이라는 이름이 6번과 7번 행에서 중복되어 True로, 'Nate'라는 이름 또한 중복되어 5행 또한 True로 출력되는 것을 알 수 있습니다.
이제 중복되는 행을 제거해보겠습니다. 이 경우에도 이 전과 마찬가지로 drop_duplicates 함수에 특정 컬럼명을 입력하여 특정 행에 대한 중복된 데이터를 제거합니다. 여기서 중복된 행을 제거할 때, 앞에 있는 행을 제거할지 아님 뒤에 있는 행을 제거할지 선택할 수 있는 옵션이 있습니다.
df.drop_duplicates(['name'], keep='first') # 앞의 행 유지
df.drop_duplicates(['name'], keep='last') # 뒤의 행 유지두 결과를 자세히 살펴보면 John이라는 이름의 데이터가 3개가 있었는데 첫 번째, 'first'의 경우 첫 번째 John을 제외한 나머지 두 행이 제거되었음을 알 수 있습니다.
또한 'last'인 경우 가장 마지막에 있던 전공이 Economics 였던 John의 데이터만을 남기고 나머지 두 행이 제거되었음을 알 수 있습니다. keep 옵션의 경우 default 값은 'first'이므로 마지막 중복 값만 남길 경우 keep 옵션에 'last' 값을 지정해주어야 합니다.
오늘은 pandas에서 groupby 함수로 데이터 그룹을 만드는 법과 duplicated 함수로 중복 데이터 여부를 검사하고, drop_duplicates 함수로 중복 데이터를 삭제하는 방법에 대해 알아보았습니다. 다음 포스팅에서는 apply 함수에 대해 집중적으로 다뤄보는 글을 써보겠습니다.
'Study > Python' 카테고리의 다른 글
| [Python]Pandas basic 파이썬 판다스 기초 : map, applymap 함수 활용하기 (0) | 2021.08.18 |
|---|---|
| [Python]Pandas basic 파이썬 판다스 기초 : apply 활용하기 (0) | 2021.08.18 |
| [Python]Pandas basic 파이썬 판다스 기초 : 행,열 생성 및 수정하기 (1) | 2021.07.14 |
| [Python]Pandas basic 파이썬 판다스 기초 : 행,열 삭제 (0) | 2021.06.30 |
| [Python]Pandas Basic 파이썬 판다스 기본 : 데이터프레임 다루기 (0) | 2021.06.28 |