
지난 포스팅에서는 pandas에서 groupby함수로 데이터 그룹을 만드는 방법과 duplicated 함수를 통해 중복데이터 여부를 검사하고, drop_duplicates 함수를 이용해 중복 데이터를 삭제하는 방법에 대해 다뤄보았습니다.
[Python]Pandas basic 파이썬 판다스 기초 : 데이터 그룹 만들기, 중복 데이터 삭제
지난 포스팅에서는 DataFrame에서 행이나 열을 삭제하지 않고 수정하거나 새로운 행, 열을 만들어 내는 방법에 대해 글을 써보았습니다. [Python]Pandas basic 파이썬 판다스 기초 : 행,열 생성 및 수정
seoyuun22.tistory.com
이번 포스팅에서는 함수 apply를 활용하는 방법에 대해 알아보겠습니다.
10. apply
apply 함수는 함수에 전달된 개체는 인덱스가 DataFrame의 인덱스( axis=0) 또는 DataFrame의 열( axis=1) 인 Series 개체입니다 . 기본적으로 최종 반환 유형은 적용된 함수의 반환 유형에서 유추됩니다. 그렇지 않으면 result_type 인수 에 따라 다릅니다.
다음 예제를 통해 apply 함수가 적용되는 예를 보겠습니다. 아래 코드를 실행하면 다음과 같은 DataFrame이 생성됩니다.
import pandas as pd
import numpy as np
df = pd.DataFrame([[4, 9]] * 3, columns=['A', 'B']
df
apply에서 축을 지정하는 axis 옵션을통해 행, 열을 기준으로 합을 구해보겠습니다.
# 열기준 합
df.apply(np.sum, axis=0)
# 행 기준 합
df.apply(np.sum, axis=1)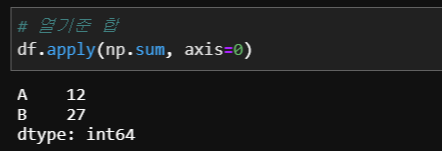

값들의 합을 구하는 numpy의 sum 함수를 통해 DataFrame의 값들을 전달 받아 합을 구합니다. 단 axis 옵션을 통해 합을 구할 기준 축을 정해주어 apply가 실행 됩니다. 마치 우리가 알던 for문 대신 DataFrame에서 값을 하나 씩 불러내는 역할을 한다는 걸 알 수 있습니다.
1. 하나의 column을 이용하여 apply function 만들기
위에서 봤던 예제는 sum이라는 이미 내장되어 있는 함수를 이용했다면, 이번에는 사용자가 만든 함수를 바탕으로 apply함수를 실행해보겠습니다. 이를 위해 예제 DataFrame을 생성하는 다음의 코드를 실행합니다.
- 날짜 column에서 연도 정보로 새 column 만들기
data_list = [{'yyyy-mm-dd' : '2015-12-29'},
{'yyyy-mm-dd' : '1996-08-21'},
{'yyyy-mm-dd' : '1989-08-18'}]
df = pd.DataFrame(data_list, columns=['yyyy-mm-dd'])위 코드를 실행하면 아래와 같은 DataFrame이 생성되는 것을 확인할 수 있습니다.
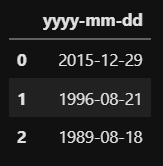
이제 이 DataFrame에서 apply를 사용하여 새로운 column을 만들겠습니다. 'yyyy-mm-dd' column에서 연도 정보만을 출력하여 'year'라는 새로운 column을 만들어보겠습니다.
그 전에 year 정보만을 가져올 수 있는 함수를 정의해보겠습니다.
def extract_year(column):
return column.split("-")[0]extract_year라는 함수를 통해 column을 받아오면 split 함수를 통해 "-"로 구분하여 쪼갭니다.(split) 그 중 0번째, 즉 연도 정보만을 return하는 역할을 extract_year 함수가 합니다. 이처럼 사용자가 정의한 함수를 통해 apply 함수를 사용해보겠습니다.
df['year'] = df['yyyy-mm-dd'].apply(extract_year)df에 'year'라는 새로운 column을 정의합니다. df에 있던 'yyyy-mm-dd'라는 column을 apply 하여 extract_year 함수를 실행 시켜 df를 확인해보면 다음과 같이 DataFrame에 year column이 생성됨을 확인할 수 있습니다.
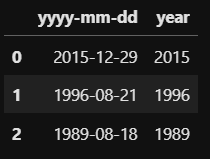
다른 예제로 이번엔 df의 year column을 받아 현재 나이를 계산하여 age column을 만들어 보겠습니다.
age는 현재 연도를 current_year로 입력받아 year 값을 빼 1을 더해 구할 수 있습니다. 이를 먼저 함수로 구현한 후 apply 함수에 적용해보겠습니다.
def get_age(year, current_year):
return current_year - int(year) + 1df['age'] = df['year'].apply(get_age, current_year = 2021)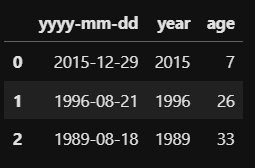
2. 2개의 column을 이용하여 apply function 만들기
이 전까지는 하나의 column만을 이용하여 새 apply를 사용해봤다면, 이번에는 2개의 column을 사용해보겠습니다. 예제는 위에서 만들었던 DataFrame을 이어서 사용해보겠습니다. 위에서 만들었던 DataFrame에는 날짜 정보의 'yyyy-mm-dd'와 여기서 연도 정보만을 갖고 온 'year', 이를 이용한 현재 나이 정보를 'age'라는 column에 담아두었습니다.
여기서 year 정보와 age 정보를 불러와 나의 생년과 나이를 소개하는 문장을 만들어 보겠습니다. 아까와 마찬가지로, apply 하기 전에 소개하는 문장을 출력하는 get_introduce 함수를 만들어보겠습니다.
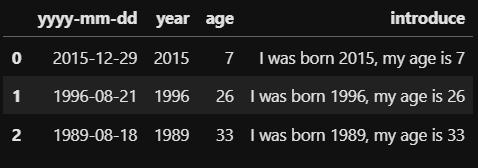
def get_introduce(row):
return "I was born " + str(row.year) + ", my age is " + str(row.age)df['introduce'] = df.apply(get_introduce, axis=1)df에서 year와 age를 불러오기위해 df에 바로 apply 함수를 적용하고, 열 기준으로 불러오기 때문에 axis 옵션을 1로 지정하여 불러옵니다. 위 코드를 모두 실행하면 아래와 같이 소개문이 작성된 introduce column이 새로 생긴 것을 확인할 수 있습니다.
오늘은 apply 함수를 활용하여 반복문 for 대신하여 dataframe의 정보를 하나씩 받아 새로운 column을 만드는 연습을 해보았습니다. 다음 포스팅에서는 map 함수와 applymap함수에 대해 알아보겠습니다.
'Study > Python' 카테고리의 다른 글
| [Python] 데이터 로드 및 전처리 (0) | 2021.10.15 |
|---|---|
| [Python]Pandas basic 파이썬 판다스 기초 : map, applymap 함수 활용하기 (0) | 2021.08.18 |
| [Python]Pandas basic 파이썬 판다스 기초 : 데이터 그룹 만들기, 중복 데이터 삭제 (0) | 2021.08.12 |
| [Python]Pandas basic 파이썬 판다스 기초 : 행,열 생성 및 수정하기 (1) | 2021.07.14 |
| [Python]Pandas basic 파이썬 판다스 기초 : 행,열 삭제 (0) | 2021.06.30 |
지난 포스팅에서는 pandas에서 groupby함수로 데이터 그룹을 만드는 방법과 duplicated 함수를 통해 중복데이터 여부를 검사하고, drop_duplicates 함수를 이용해 중복 데이터를 삭제하는 방법에 대해 다뤄보았습니다.
[Python]Pandas basic 파이썬 판다스 기초 : 데이터 그룹 만들기, 중복 데이터 삭제
지난 포스팅에서는 DataFrame에서 행이나 열을 삭제하지 않고 수정하거나 새로운 행, 열을 만들어 내는 방법에 대해 글을 써보았습니다. [Python]Pandas basic 파이썬 판다스 기초 : 행,열 생성 및 수정
seoyuun22.tistory.com
이번 포스팅에서는 함수 apply를 활용하는 방법에 대해 알아보겠습니다.
10. apply
apply 함수는 함수에 전달된 개체는 인덱스가 DataFrame의 인덱스( axis=0) 또는 DataFrame의 열( axis=1) 인 Series 개체입니다 . 기본적으로 최종 반환 유형은 적용된 함수의 반환 유형에서 유추됩니다. 그렇지 않으면 result_type 인수 에 따라 다릅니다.
다음 예제를 통해 apply 함수가 적용되는 예를 보겠습니다. 아래 코드를 실행하면 다음과 같은 DataFrame이 생성됩니다.
import pandas as pd
import numpy as np
df = pd.DataFrame([[4, 9]] * 3, columns=['A', 'B']
dfapply에서 축을 지정하는 axis 옵션을통해 행, 열을 기준으로 합을 구해보겠습니다.
# 열기준 합
df.apply(np.sum, axis=0)
# 행 기준 합
df.apply(np.sum, axis=1)값들의 합을 구하는 numpy의 sum 함수를 통해 DataFrame의 값들을 전달 받아 합을 구합니다. 단 axis 옵션을 통해 합을 구할 기준 축을 정해주어 apply가 실행 됩니다. 마치 우리가 알던 for문 대신 DataFrame에서 값을 하나 씩 불러내는 역할을 한다는 걸 알 수 있습니다.
1. 하나의 column을 이용하여 apply function 만들기
위에서 봤던 예제는 sum이라는 이미 내장되어 있는 함수를 이용했다면, 이번에는 사용자가 만든 함수를 바탕으로 apply함수를 실행해보겠습니다. 이를 위해 예제 DataFrame을 생성하는 다음의 코드를 실행합니다.
- 날짜 column에서 연도 정보로 새 column 만들기
data_list = [{'yyyy-mm-dd' : '2015-12-29'},
{'yyyy-mm-dd' : '1996-08-21'},
{'yyyy-mm-dd' : '1989-08-18'}]
df = pd.DataFrame(data_list, columns=['yyyy-mm-dd'])위 코드를 실행하면 아래와 같은 DataFrame이 생성되는 것을 확인할 수 있습니다.
이제 이 DataFrame에서 apply를 사용하여 새로운 column을 만들겠습니다. 'yyyy-mm-dd' column에서 연도 정보만을 출력하여 'year'라는 새로운 column을 만들어보겠습니다.
그 전에 year 정보만을 가져올 수 있는 함수를 정의해보겠습니다.
def extract_year(column):
return column.split("-")[0]extract_year라는 함수를 통해 column을 받아오면 split 함수를 통해 "-"로 구분하여 쪼갭니다.(split) 그 중 0번째, 즉 연도 정보만을 return하는 역할을 extract_year 함수가 합니다. 이처럼 사용자가 정의한 함수를 통해 apply 함수를 사용해보겠습니다.
df['year'] = df['yyyy-mm-dd'].apply(extract_year)df에 'year'라는 새로운 column을 정의합니다. df에 있던 'yyyy-mm-dd'라는 column을 apply 하여 extract_year 함수를 실행 시켜 df를 확인해보면 다음과 같이 DataFrame에 year column이 생성됨을 확인할 수 있습니다.
다른 예제로 이번엔 df의 year column을 받아 현재 나이를 계산하여 age column을 만들어 보겠습니다.
age는 현재 연도를 current_year로 입력받아 year 값을 빼 1을 더해 구할 수 있습니다. 이를 먼저 함수로 구현한 후 apply 함수에 적용해보겠습니다.
def get_age(year, current_year):
return current_year - int(year) + 1df['age'] = df['year'].apply(get_age, current_year = 2021)
2. 2개의 column을 이용하여 apply function 만들기
이 전까지는 하나의 column만을 이용하여 새 apply를 사용해봤다면, 이번에는 2개의 column을 사용해보겠습니다. 예제는 위에서 만들었던 DataFrame을 이어서 사용해보겠습니다. 위에서 만들었던 DataFrame에는 날짜 정보의 'yyyy-mm-dd'와 여기서 연도 정보만을 갖고 온 'year', 이를 이용한 현재 나이 정보를 'age'라는 column에 담아두었습니다.
여기서 year 정보와 age 정보를 불러와 나의 생년과 나이를 소개하는 문장을 만들어 보겠습니다. 아까와 마찬가지로, apply 하기 전에 소개하는 문장을 출력하는 get_introduce 함수를 만들어보겠습니다.
def get_introduce(row):
return "I was born " + str(row.year) + ", my age is " + str(row.age)df['introduce'] = df.apply(get_introduce, axis=1)df에서 year와 age를 불러오기위해 df에 바로 apply 함수를 적용하고, 열 기준으로 불러오기 때문에 axis 옵션을 1로 지정하여 불러옵니다. 위 코드를 모두 실행하면 아래와 같이 소개문이 작성된 introduce column이 새로 생긴 것을 확인할 수 있습니다.
오늘은 apply 함수를 활용하여 반복문 for 대신하여 dataframe의 정보를 하나씩 받아 새로운 column을 만드는 연습을 해보았습니다. 다음 포스팅에서는 map 함수와 applymap함수에 대해 알아보겠습니다.
'Study > Python' 카테고리의 다른 글
| [Python] 데이터 로드 및 전처리 (0) | 2021.10.15 |
|---|---|
| [Python]Pandas basic 파이썬 판다스 기초 : map, applymap 함수 활용하기 (0) | 2021.08.18 |
| [Python]Pandas basic 파이썬 판다스 기초 : 데이터 그룹 만들기, 중복 데이터 삭제 (0) | 2021.08.12 |
| [Python]Pandas basic 파이썬 판다스 기초 : 행,열 생성 및 수정하기 (1) | 2021.07.14 |
| [Python]Pandas basic 파이썬 판다스 기초 : 행,열 삭제 (0) | 2021.06.30 |