
지난 포스팅에서는 DataFrame에서 행과 열을 삭제하는 방법에 대해서 소개해보았습니다.
DataFrame에서 행 또는 열을 삭제할 때는 drop 함수를 주로 사용했고, drop 함수를 사용하면서 여러 옵션에 대해 알아보고 사용해보았습니다. 오늘은 DataFrame에서 행이나 열을 삭제하지 않고 수정하거나 새로운 행, 열을 만들어 내는 방법에 대해 소개해보겠습니다.
[Python]Pandas basic 파이썬 판다스 기초 : 행,열 삭제
지난 포스팅에서 DataFrame에서 행, 열을 중심으로 선택, 필터링 하는 방법에 대해 소개해보았습니다. DataFrame의 행을 선택할 때는 인덱스, loc함수, 컬럼의 조건을 통한 검색 등 다양한 방법이 있었
seoyuun22.tistory.com
7. Row, Column Create, Update
데이터가 필요 없다고 해도 항상 삭제만 할 수 없는 노릇입니다. 아주 간단하게 수정할 수 있다면 굳이 삭제하고 DataFrame을 다시 만들 필요가 없으니깐요. 이번 시간에는 새로운 행과 열을 추가하거나 수정하는 방법에 대해 다뤄보겠습니다.
1) Create & Up date Column
먼저 아래 코드를 이용하여 DataFrame에 열을 추가해보겠습니다.
import pandas as pd
friend_dic_list = [
{'name' : 'Jone', 'age' : 14, 'job' : 'student'},
{'name' : 'Jenny', 'age' : 30, 'job' : 'developer'},
{'name' : 'Nate', 'age' : 30, 'job' : 'teacher'}
]
df = pd.DataFrame(friend_dic_list, columns=['name', 'age','job'])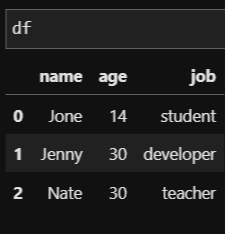
위의 코드를 작성해 실행해보면 name, age, job 정보를 담고 있는 DataFrame이 만들어집니다. 여기서 우리는 수입 정보인 'salary'를 추가해보겠습니다.
1. 새로 만들 컬럼명에 데이터 넣기
# df['컬럼명'] = 임의의 데이터
df['salary'] = 0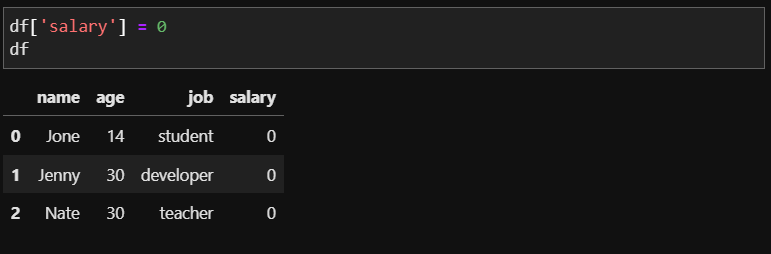
먼저 새로 만들 컬럼의 이름을 이용하여 임의의 데이터를 저장해 놓습니다. 이후 df를 보면 모든 salary가 0으로 입력되어 있음을 확인할 수 있습니다. 해당 열에 모두 같은 값을 넣을 때는 단순한 등호로 쉽게 만들 수 있습니다.
2. numpy를 사용하여 조건을 만족하는 컬럼에 정보 입력하기
위에서 만들었던 데이터를 바탕으로 salary 정보를 수정하기 위해서 numpy 모듈을 사용해보겠습니다.
Numpy
numpy 모듈은 파이썬에서 수학, 과학 연산을 위한 모듈로 주로 수치해석, 통계 관련한 분석을 실시할 때 자주 사용되는 모듈입니다. pandas 만큼 자주 쓰이는 모듈이기 때문에 파이썬으로 관련 분야에 도전하고자 한다면 반드시 이에 대한 기초를 잘 쌓아두는 것이 좋습니다. 또한 numpy는 주로 np로 호출합니다.

numpy를 호출한 후, numpy의 where 함수를 활용하여 정보를 수정합니다.
df의 'job' 열의 정보가 'student'가 아닌 것에 대해서만 salary에 'yes'라는 문자열을 넣고, job이 student에 해당하면 'no'라는 문자열을 넣을 것입니다. 그렇다면 위 결과는 어떻게 될까요?
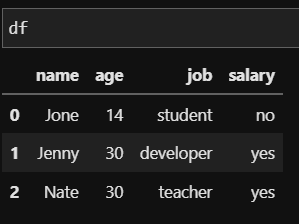
job이 student 인 Jone을 제외한 나머지는 salary가 'yes'로 변경되었고, Jone은 student 이기 때문에 no가 입력되어 있는 것을 확인할 수 있습니다. 이처럼 numpy의 where을 이용하면 if else문과 같은 효과로 열에 데이터를 수정할 수 있습니다. where 함수를 정리하면 다음과 같습니다.
df['col1'] = np.werhe(condition, true, false)condition(조건)을 만족한다면 true를, 만족하지 않는 다면 false에 입력된 정보를 df라는 DataFrame에 'col1'이라는 컬럼에 넣을 것이라는 의미를 갖고 있습니다.
3. 기존 컬럼을 활용하여 새로운 컬럼 만들기
새로운 컬럼을 만드는 방법 중, 기존에 있는 숫자형 컬럼들을 연산과정 등을 통해 새로운 컬럼을 만드는 방법이 있습니다. 이를 확인해 보기 위해 새로운 DataFrame을 만들어 보겠습니다.
friend_dic_list = [
{'name' : 'Jone', 'midterm' : 95, 'final' : 85},
{'name' : 'Jenny', 'midterm' : 85, 'final' : 80},
{'name' : 'Nate', 'midterm' : 30, 'final' : 10}
]
df = pd.DataFrame(friend_dic_list, columns = ['name', 'midterm', 'final'])위의 코드를 입력하면 아래와 같은 DataFrame이 생성됩니다.
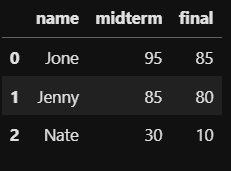
위에서 생성된 DataFrame에 midterm(중간고사) 정보와 final(기말고사) 정보를 통해 통합 점수인 total 컬럼을 만들어 보겠습니다. 만드는 방법은 다음과 같습니다.
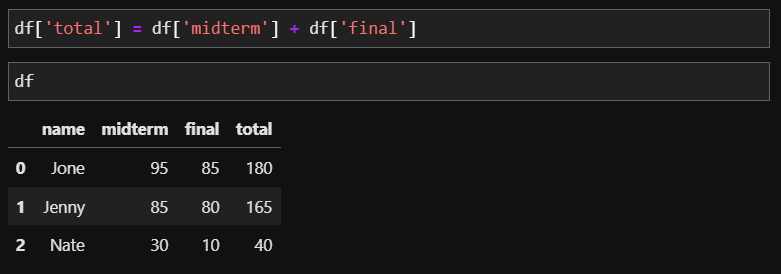
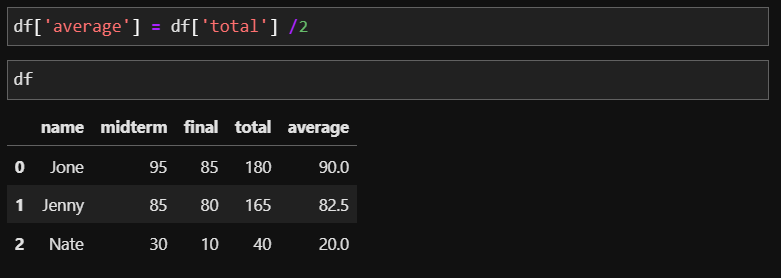
df에 새로 만들 컬럼 (=total) 은 df에 midtem과 final 컬럼의 숫자를 각 행에 맞춰 더해 만들 수 있습니다. 위와 같은 방법으로 성적의 평균 정보를 담는 'average' 컬럼을 만든다면 total 점수를 2로 나누어 주면 만들 수 있겠죠?
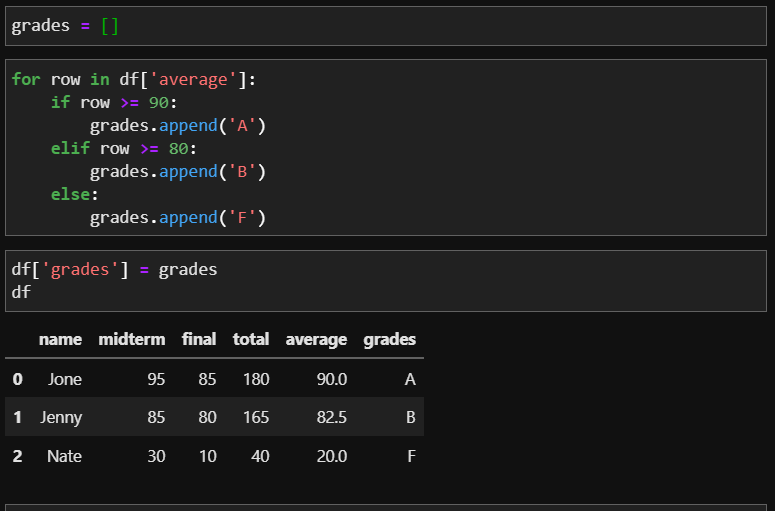
이번에는 리스트를 활용해 평균에 따른 등급을 입력해보겠습니다. 평균이 90점 이상이면 A, 평균이 80점 이상이면 B, 그 외 점수는 F를 입력해보겠습니다. 여기서 for문과 if-else문을 활용될 예정입니다.
먼저 등급정보를 담을 빈 리스트를 만들어 주고
grades = []for 문에서 평균값을 하나씩 불러냅니다
for row in df['average']:for문을 통해 평균값을 하나씩 비교합니다. 조건은 평균이 90점 이상이면 A, 평균이 80점 이상이면 B, 그 외 점수는 F를 if 문과 append 함수를 이용하여 grades 리스트에 담을 겁니다. 이때 리스트에 담는 역할을 하는 게 append 함수입니다.
for row in df['average']:
if row >= 90:
grades.append('A')
elif row >= 80:
grades.append('B')
else:
grades.append('F')append
append는 단어의 뜻 그대로 덧붙이다, 첨부하다 라는 뜻으로 리스트의 맨 마지막에 데이터를 추가하는 함수입니다. 리스트 안에는 어떤 자료형도 추가할 수 있기 때문에 append 함수 안에도 다양한 자료형이 입력될 수 있습니다.
이렇게 만들어진 리스트를 이제 df의 'grades' 컬럼에 넣어주면 끝!
df['grades'] = grades위 과정을 풀버전으로 보면 다음과 같이 DataFrame에 grades 컬럼이 생긴 것을 확인할 수 있습니다.
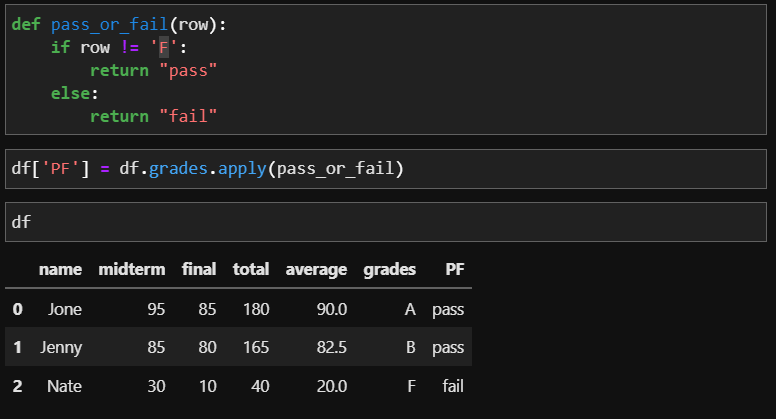
이번에는 Pass와 Fail를 판별하는 함수를 만들어 새로운 컬럼을 만들어 보겠습니다. Pass와 Fail의 기준은 등급이 F이면 Fail, 나머지는 Pass로 하겠습니다. 함수를 만들 때도 if문을 사용하면 되겠죠?
def pass_or_fail(row):
if row != 'F':
return "Pass"
else:
return "Fail"위와 같이 함수를 만들어 새로운 컬럼에 정보를 넣거나 또는 기존 컬럼을 수정할 수 있습니다. 여기서 함수를 적용하여 데이터를 입력할 때 apply 함수를 사용합니다.
apply
apply 함수는 DataFrame의 컬럼에 복잡한 연산을 vertorizing 할 수 있게 해주는 함수로, 자주 사용되는 함수입니다. 간단히 lambda 함수를 적용할 뿐만 아니라 위와 같이 사용자가 정의한 함수도 적용할 수 있는 함수입니다.
df.grades = df.grades.apply(pass_or_fail)
df['P/F'] = df.grades.apply(pass_or_fail)이와 같은 과정을 풀버전으로 확인하면 다음과 같습니다. 저는 새로 'P/F'라는 컬럼을 만들어보았습니다.
2) Create & Up date row
1. 기존 DataFrame에 새 DataFrame 추가하기
행을 추가하는 방법임과 동시에 DataFrame과 DataFrame을 합치는 방법이라 할 수 있습니다. 먼저 위에서 작성했던 'friend_dic_list'를 바탕으로 만들어진 DataFrame을 예시로 들어보겠습니다.
friend_dic_list = [
{'name' : 'Jone', 'midterm' : 95, 'final' : 85},
{'name' : 'Jenny', 'midterm' : 85, 'final' : 80},
{'name' : 'Nate', 'midterm' : 30, 'final' : 10}
]
df = pd.DataFrame(friend_dic_list, columns = ['name', 'midterm', 'final'])아까 위에서 예시로 봤던 DataFrame과 동일합니다. 이제 이 DataFrame에 새로운 DataFrame을 합쳐줄 예정입니다. 그 전에 먼저 새로운 DataFrame도 간단히 정의해보겠습니다.
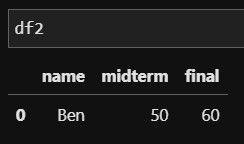
df2 = pd.DataFrame([
['Ben', 50, 60]], columns = ['name', 'midterm', 'final')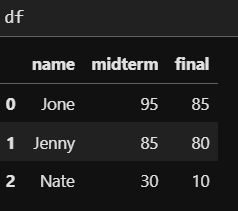

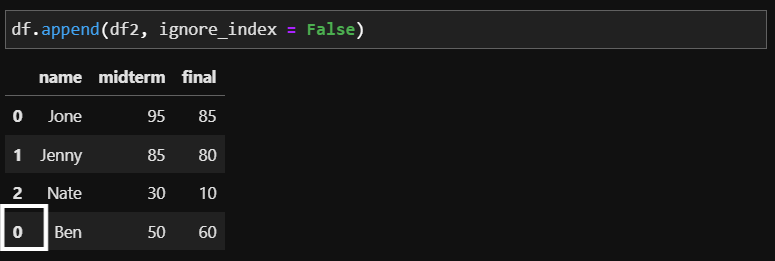
이제 기존에 있던 df에 df2를 합쳐보겠습니다. 합칠때는 앞에서 봤던 append 함수를 이용합니다. 여기서 주의해야 할점은 df2의 index입니다. Ben의 정보는 df2에서 0번 인덱스를 갖지만 df에는 이미 0번에 Jone의 정보가 있습니다. 그럼 Ben은 Nate 다음인 3번 자리에 들어가야 합니다. 이러한 인덱스의 혼란을 방지하기 위해 append 함수에서 ignore_index 옵션이 필요합니다. ignore_index는 인덱스 이름 무시 여부를 의미합니다. 자세한 것은 ignore_index가 False일때, True일때 비교를 해보면 확연한 차이를 확인할 수 있습니다.
ignore_index = False의 경우
ignore_index = True
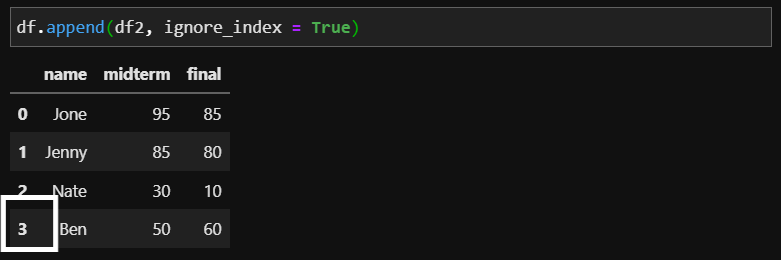
차이를 확인하셨나요? 바로 Ben의 인덱스 입니다. ignore_index가 False 일때는 Ben의 인덱스가 0입니다. df2에서의 인덱스를 무시하지 않고 그대로 가져왔기 때문이죠. 하지만 ignore_index가 True이게 되면 이전 인덱스는 무시하게 되어 df에서의 새로운 인덱스를 갖게 됩니다.
2. loc[index] 메소드 사용하기
loc[index]는 새로운리스트를 새로운 행으로 가져 와서 주어진 Dataframe의 index에 추가합니다. 이번에도 위에서 사용한 friend_dic_list를 바탕으로 만든 DataFrame을 이용하여 Ben의 정보를 추가해보겠습니다.
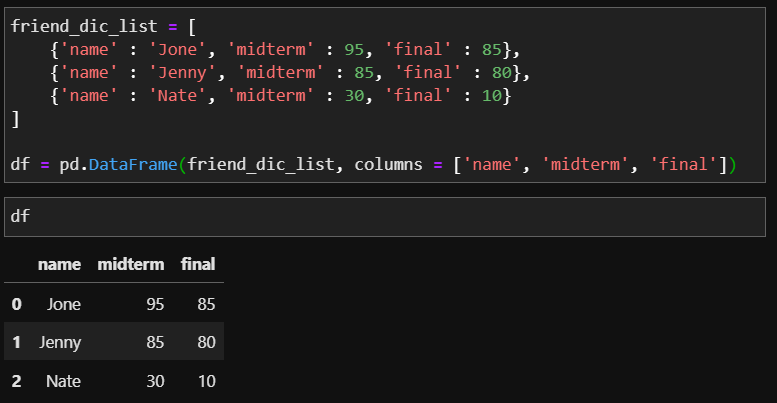
loc 메소드를 사용할 때 중요한 점은 index입니다. 이전에 봤던 append를 사용해 행을 추가할 때는 무조건 마지막 인덱스를 갖게 되었지만 loc메소드를 이용하면 추가하고 싶은 행을 특정 인덱스에 추가할 수 있는 장점이 있습니다.
만약 인덱스가 2번까지만 있는 df의 4번 인덱스에 Ben의 정보를 넣는다고 하면 다음과 같이 작성할 수 있습니다.
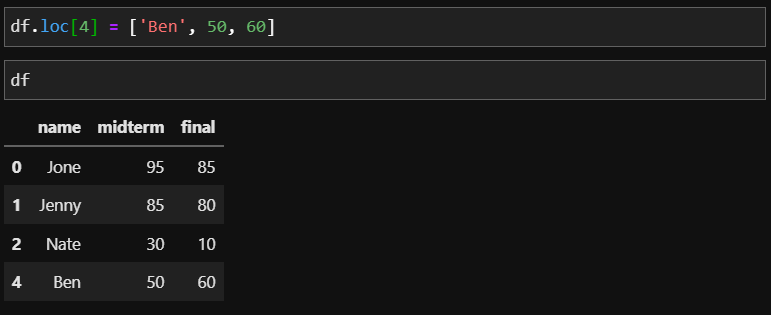
이렇게 해서 행 또는열에 추가하고, 수정하는 방법까지 살펴보았습니다. 다양한 방법이 있으니 본인에게 편하거나 상황에 맞게 쓰면 아주 유용하게 쓰이니 많이 복습해보세요!! 저는 다음 포스팅에서 데이터 그룹을 만드는 방법에 대해 올리도록 하겠습니다!
'Study > Python' 카테고리의 다른 글
| [Python]Pandas basic 파이썬 판다스 기초 : apply 활용하기 (0) | 2021.08.18 |
|---|---|
| [Python]Pandas basic 파이썬 판다스 기초 : 데이터 그룹 만들기, 중복 데이터 삭제 (0) | 2021.08.12 |
| [Python]Pandas basic 파이썬 판다스 기초 : 행,열 삭제 (0) | 2021.06.30 |
| [Python]Pandas Basic 파이썬 판다스 기본 : 데이터프레임 다루기 (0) | 2021.06.28 |
| [Python] pandas basic 파이썬 판다스 기본 : DataFrame 만들기, 저장하기 (0) | 2021.06.23 |
지난 포스팅에서는 DataFrame에서 행과 열을 삭제하는 방법에 대해서 소개해보았습니다.
DataFrame에서 행 또는 열을 삭제할 때는 drop 함수를 주로 사용했고, drop 함수를 사용하면서 여러 옵션에 대해 알아보고 사용해보았습니다. 오늘은 DataFrame에서 행이나 열을 삭제하지 않고 수정하거나 새로운 행, 열을 만들어 내는 방법에 대해 소개해보겠습니다.
[Python]Pandas basic 파이썬 판다스 기초 : 행,열 삭제
지난 포스팅에서 DataFrame에서 행, 열을 중심으로 선택, 필터링 하는 방법에 대해 소개해보았습니다. DataFrame의 행을 선택할 때는 인덱스, loc함수, 컬럼의 조건을 통한 검색 등 다양한 방법이 있었
seoyuun22.tistory.com
7. Row, Column Create, Update
데이터가 필요 없다고 해도 항상 삭제만 할 수 없는 노릇입니다. 아주 간단하게 수정할 수 있다면 굳이 삭제하고 DataFrame을 다시 만들 필요가 없으니깐요. 이번 시간에는 새로운 행과 열을 추가하거나 수정하는 방법에 대해 다뤄보겠습니다.
1) Create & Up date Column
먼저 아래 코드를 이용하여 DataFrame에 열을 추가해보겠습니다.
import pandas as pd
friend_dic_list = [
{'name' : 'Jone', 'age' : 14, 'job' : 'student'},
{'name' : 'Jenny', 'age' : 30, 'job' : 'developer'},
{'name' : 'Nate', 'age' : 30, 'job' : 'teacher'}
]
df = pd.DataFrame(friend_dic_list, columns=['name', 'age','job'])위의 코드를 작성해 실행해보면 name, age, job 정보를 담고 있는 DataFrame이 만들어집니다. 여기서 우리는 수입 정보인 'salary'를 추가해보겠습니다.
1. 새로 만들 컬럼명에 데이터 넣기
# df['컬럼명'] = 임의의 데이터
df['salary'] = 0먼저 새로 만들 컬럼의 이름을 이용하여 임의의 데이터를 저장해 놓습니다. 이후 df를 보면 모든 salary가 0으로 입력되어 있음을 확인할 수 있습니다. 해당 열에 모두 같은 값을 넣을 때는 단순한 등호로 쉽게 만들 수 있습니다.
2. numpy를 사용하여 조건을 만족하는 컬럼에 정보 입력하기
위에서 만들었던 데이터를 바탕으로 salary 정보를 수정하기 위해서 numpy 모듈을 사용해보겠습니다.
Numpy
numpy 모듈은 파이썬에서 수학, 과학 연산을 위한 모듈로 주로 수치해석, 통계 관련한 분석을 실시할 때 자주 사용되는 모듈입니다. pandas 만큼 자주 쓰이는 모듈이기 때문에 파이썬으로 관련 분야에 도전하고자 한다면 반드시 이에 대한 기초를 잘 쌓아두는 것이 좋습니다. 또한 numpy는 주로 np로 호출합니다.
numpy를 호출한 후, numpy의 where 함수를 활용하여 정보를 수정합니다.
df의 'job' 열의 정보가 'student'가 아닌 것에 대해서만 salary에 'yes'라는 문자열을 넣고, job이 student에 해당하면 'no'라는 문자열을 넣을 것입니다. 그렇다면 위 결과는 어떻게 될까요?
job이 student 인 Jone을 제외한 나머지는 salary가 'yes'로 변경되었고, Jone은 student 이기 때문에 no가 입력되어 있는 것을 확인할 수 있습니다. 이처럼 numpy의 where을 이용하면 if else문과 같은 효과로 열에 데이터를 수정할 수 있습니다. where 함수를 정리하면 다음과 같습니다.
df['col1'] = np.werhe(condition, true, false)condition(조건)을 만족한다면 true를, 만족하지 않는 다면 false에 입력된 정보를 df라는 DataFrame에 'col1'이라는 컬럼에 넣을 것이라는 의미를 갖고 있습니다.
3. 기존 컬럼을 활용하여 새로운 컬럼 만들기
새로운 컬럼을 만드는 방법 중, 기존에 있는 숫자형 컬럼들을 연산과정 등을 통해 새로운 컬럼을 만드는 방법이 있습니다. 이를 확인해 보기 위해 새로운 DataFrame을 만들어 보겠습니다.
friend_dic_list = [
{'name' : 'Jone', 'midterm' : 95, 'final' : 85},
{'name' : 'Jenny', 'midterm' : 85, 'final' : 80},
{'name' : 'Nate', 'midterm' : 30, 'final' : 10}
]
df = pd.DataFrame(friend_dic_list, columns = ['name', 'midterm', 'final'])위의 코드를 입력하면 아래와 같은 DataFrame이 생성됩니다.
위에서 생성된 DataFrame에 midterm(중간고사) 정보와 final(기말고사) 정보를 통해 통합 점수인 total 컬럼을 만들어 보겠습니다. 만드는 방법은 다음과 같습니다.
df에 새로 만들 컬럼 (=total) 은 df에 midtem과 final 컬럼의 숫자를 각 행에 맞춰 더해 만들 수 있습니다. 위와 같은 방법으로 성적의 평균 정보를 담는 'average' 컬럼을 만든다면 total 점수를 2로 나누어 주면 만들 수 있겠죠?
이번에는 리스트를 활용해 평균에 따른 등급을 입력해보겠습니다. 평균이 90점 이상이면 A, 평균이 80점 이상이면 B, 그 외 점수는 F를 입력해보겠습니다. 여기서 for문과 if-else문을 활용될 예정입니다.
먼저 등급정보를 담을 빈 리스트를 만들어 주고
grades = []for 문에서 평균값을 하나씩 불러냅니다
for row in df['average']:for문을 통해 평균값을 하나씩 비교합니다. 조건은 평균이 90점 이상이면 A, 평균이 80점 이상이면 B, 그 외 점수는 F를 if 문과 append 함수를 이용하여 grades 리스트에 담을 겁니다. 이때 리스트에 담는 역할을 하는 게 append 함수입니다.
for row in df['average']:
if row >= 90:
grades.append('A')
elif row >= 80:
grades.append('B')
else:
grades.append('F')append
append는 단어의 뜻 그대로 덧붙이다, 첨부하다 라는 뜻으로 리스트의 맨 마지막에 데이터를 추가하는 함수입니다. 리스트 안에는 어떤 자료형도 추가할 수 있기 때문에 append 함수 안에도 다양한 자료형이 입력될 수 있습니다.
이렇게 만들어진 리스트를 이제 df의 'grades' 컬럼에 넣어주면 끝!
df['grades'] = grades위 과정을 풀버전으로 보면 다음과 같이 DataFrame에 grades 컬럼이 생긴 것을 확인할 수 있습니다.
이번에는 Pass와 Fail를 판별하는 함수를 만들어 새로운 컬럼을 만들어 보겠습니다. Pass와 Fail의 기준은 등급이 F이면 Fail, 나머지는 Pass로 하겠습니다. 함수를 만들 때도 if문을 사용하면 되겠죠?
def pass_or_fail(row):
if row != 'F':
return "Pass"
else:
return "Fail"위와 같이 함수를 만들어 새로운 컬럼에 정보를 넣거나 또는 기존 컬럼을 수정할 수 있습니다. 여기서 함수를 적용하여 데이터를 입력할 때 apply 함수를 사용합니다.
apply
apply 함수는 DataFrame의 컬럼에 복잡한 연산을 vertorizing 할 수 있게 해주는 함수로, 자주 사용되는 함수입니다. 간단히 lambda 함수를 적용할 뿐만 아니라 위와 같이 사용자가 정의한 함수도 적용할 수 있는 함수입니다.
df.grades = df.grades.apply(pass_or_fail)
df['P/F'] = df.grades.apply(pass_or_fail)이와 같은 과정을 풀버전으로 확인하면 다음과 같습니다. 저는 새로 'P/F'라는 컬럼을 만들어보았습니다.
2) Create & Up date row
1. 기존 DataFrame에 새 DataFrame 추가하기
행을 추가하는 방법임과 동시에 DataFrame과 DataFrame을 합치는 방법이라 할 수 있습니다. 먼저 위에서 작성했던 'friend_dic_list'를 바탕으로 만들어진 DataFrame을 예시로 들어보겠습니다.
friend_dic_list = [
{'name' : 'Jone', 'midterm' : 95, 'final' : 85},
{'name' : 'Jenny', 'midterm' : 85, 'final' : 80},
{'name' : 'Nate', 'midterm' : 30, 'final' : 10}
]
df = pd.DataFrame(friend_dic_list, columns = ['name', 'midterm', 'final'])아까 위에서 예시로 봤던 DataFrame과 동일합니다. 이제 이 DataFrame에 새로운 DataFrame을 합쳐줄 예정입니다. 그 전에 먼저 새로운 DataFrame도 간단히 정의해보겠습니다.
df2 = pd.DataFrame([
['Ben', 50, 60]], columns = ['name', 'midterm', 'final')이제 기존에 있던 df에 df2를 합쳐보겠습니다. 합칠때는 앞에서 봤던 append 함수를 이용합니다. 여기서 주의해야 할점은 df2의 index입니다. Ben의 정보는 df2에서 0번 인덱스를 갖지만 df에는 이미 0번에 Jone의 정보가 있습니다. 그럼 Ben은 Nate 다음인 3번 자리에 들어가야 합니다. 이러한 인덱스의 혼란을 방지하기 위해 append 함수에서 ignore_index 옵션이 필요합니다. ignore_index는 인덱스 이름 무시 여부를 의미합니다. 자세한 것은 ignore_index가 False일때, True일때 비교를 해보면 확연한 차이를 확인할 수 있습니다.
ignore_index = False의 경우
ignore_index = True
차이를 확인하셨나요? 바로 Ben의 인덱스 입니다. ignore_index가 False 일때는 Ben의 인덱스가 0입니다. df2에서의 인덱스를 무시하지 않고 그대로 가져왔기 때문이죠. 하지만 ignore_index가 True이게 되면 이전 인덱스는 무시하게 되어 df에서의 새로운 인덱스를 갖게 됩니다.
2. loc[index] 메소드 사용하기
loc[index]는 새로운리스트를 새로운 행으로 가져 와서 주어진 Dataframe의 index에 추가합니다. 이번에도 위에서 사용한 friend_dic_list를 바탕으로 만든 DataFrame을 이용하여 Ben의 정보를 추가해보겠습니다.
loc 메소드를 사용할 때 중요한 점은 index입니다. 이전에 봤던 append를 사용해 행을 추가할 때는 무조건 마지막 인덱스를 갖게 되었지만 loc메소드를 이용하면 추가하고 싶은 행을 특정 인덱스에 추가할 수 있는 장점이 있습니다.
만약 인덱스가 2번까지만 있는 df의 4번 인덱스에 Ben의 정보를 넣는다고 하면 다음과 같이 작성할 수 있습니다.
이렇게 해서 행 또는열에 추가하고, 수정하는 방법까지 살펴보았습니다. 다양한 방법이 있으니 본인에게 편하거나 상황에 맞게 쓰면 아주 유용하게 쓰이니 많이 복습해보세요!! 저는 다음 포스팅에서 데이터 그룹을 만드는 방법에 대해 올리도록 하겠습니다!
'Study > Python' 카테고리의 다른 글
| [Python]Pandas basic 파이썬 판다스 기초 : apply 활용하기 (0) | 2021.08.18 |
|---|---|
| [Python]Pandas basic 파이썬 판다스 기초 : 데이터 그룹 만들기, 중복 데이터 삭제 (0) | 2021.08.12 |
| [Python]Pandas basic 파이썬 판다스 기초 : 행,열 삭제 (0) | 2021.06.30 |
| [Python]Pandas Basic 파이썬 판다스 기본 : 데이터프레임 다루기 (0) | 2021.06.28 |
| [Python] pandas basic 파이썬 판다스 기본 : DataFrame 만들기, 저장하기 (0) | 2021.06.23 |